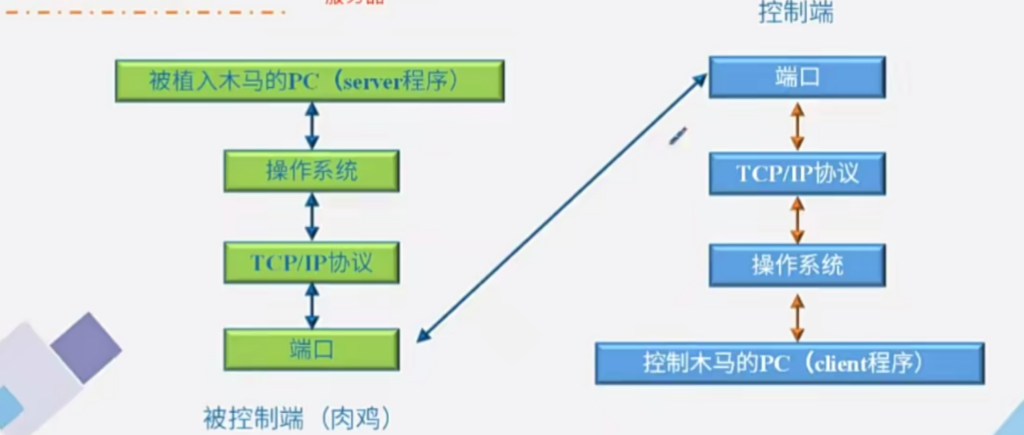
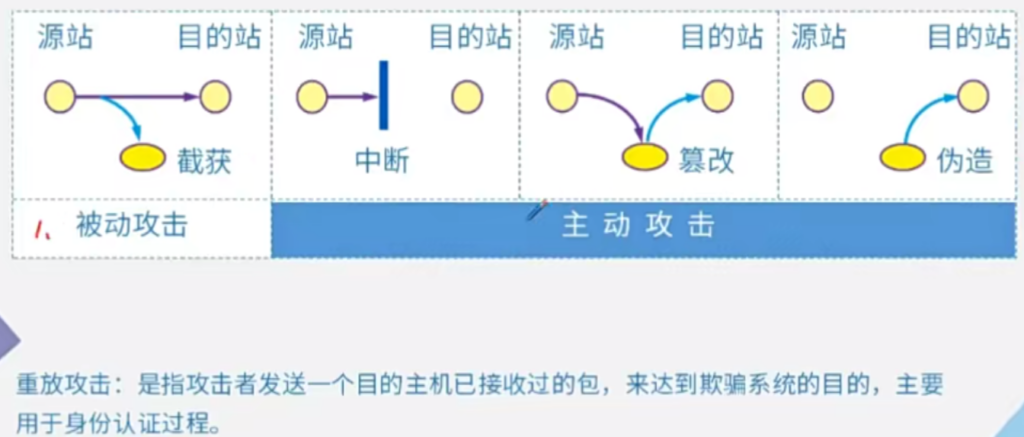
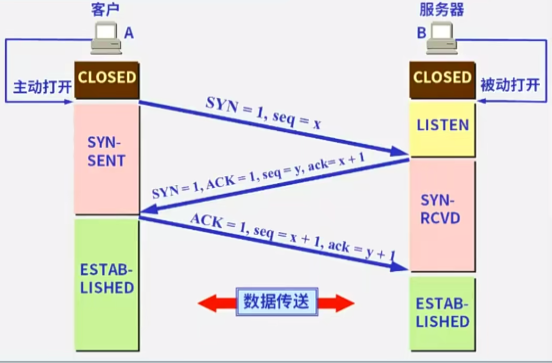
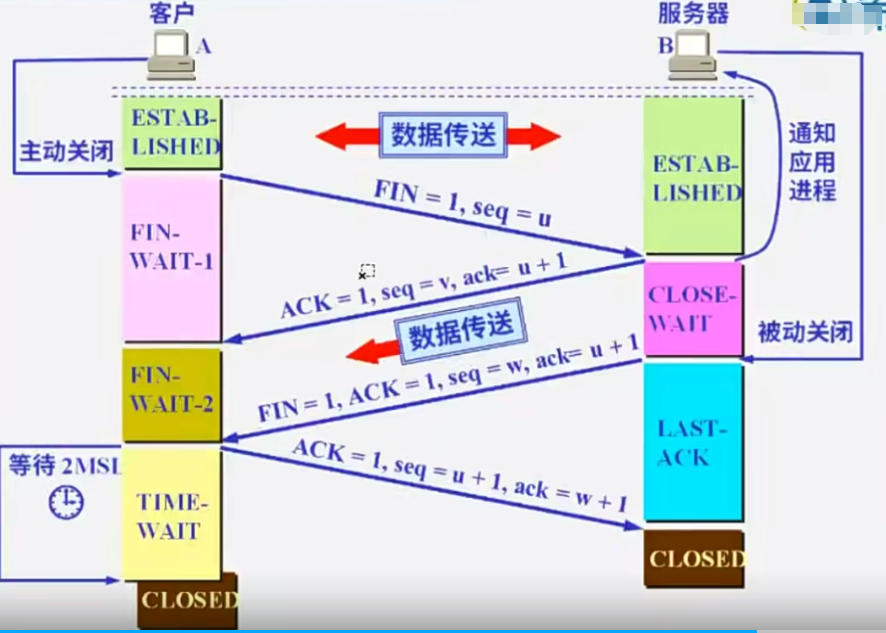
1、端口扫描
Nmap (Network Mapper)
- 简介:Nmap 是一款非常流行的开源端口扫描工具,可以进行各种类型的端口扫描,包括TCP SYN扫描、TCP Connect扫描、UDP扫描等。Nmap 还可以进行操作系统检测、服务版本检测等功能。
- 命令示例:bash深色版本
1nmap -sS -p 1-1024 192.168.1.1这条命令使用TCP SYN扫描方式扫描目标IP地址192.168.1.1的1到1024号端口。
Masscan
- 简介:Masscan 是一款超高速的大规模端口扫描工具,可以以每秒数百万个端口的速度进行扫描,适用于大规模网络环境。
- 命令示例:
masscan 192.168.1.0/24 -p 1-1024 --rate=10000
2、arp欺骗攻击、dns欺骗攻击、dhcp欺骗攻击
ARP欺骗(ARP Spoofing)是一种网络攻击方式,攻击者通过发送伪造的ARP应答报文,使得网络上的一个或多个主机误以为某个MAC地址对应的是另一个主机的IP地址。这种攻击可以用来拦截数据包,或者让目标主机与网络上的其他主机失去联系。下面是ARP欺骗攻击的基本原理:
ARP的工作原理
在理解ARP欺骗之前,首先需要了解ARP是如何工作的。ARP(Address Resolution Protocol)用于将网络层使用的IP地址解析为链路层使用的硬件地址(即MAC地址)。当一台主机想要向另一台主机发送数据包时,如果不知道目标主机的MAC地址,则会发送一个ARP请求广播,询问哪个设备拥有特定的MAC地址。网络上拥有该MAC地址的设备会回应一个ARP应答,其中包含其MAC地址。
ARP欺骗的过程
- 监听网络流量: 攻击者首先会监听网络上的ARP请求和应答,以便找到潜在的目标主机和网关。
- 伪造ARP应答: 攻击者随后会向目标主机发送伪造的ARP应答报文,声称自己拥有某个特定的IP地址(通常是网关的IP地址)。例如,攻击者会发送一个ARP应答,告诉主机A:“我是192.168.1.1(网关的IP地址),我的MAC地址是XX:XX:XX:XX:XX:XX(攻击者的MAC地址)”。
- 中间人攻击(Man-in-the-Middle Attack): 一旦主机A接受了这个虚假的ARP应答,它就会开始将数据包发送到攻击者的MAC地址,而不是真正的网关。同时,攻击者也会向网关发送类似的虚假ARP应答,声称自己是主机A。这样,所有从主机A到网关以及从网关到主机A的数据包都会经过攻击者的机器。
- 数据包拦截: 攻击者可以读取、修改或丢弃这些数据包,从而实现对网络通信的监视和操控。
ARP欺骗的影响
- 数据泄露: 攻击者可以窃听网络流量,获取敏感信息。
- 拒绝服务: 如果攻击者选择不转发数据包或延迟转发,会导致目标主机无法正常通信。
- 中间人攻击: 攻击者可以在通信双方之间插入自己,修改或注入恶意数据。
防范ARP欺骗的方法
- 使用静态ARP表: 将已知的IP地址和MAC地址绑定在一起,避免动态ARP解析。
- ARP防护技术: 如ARP Inspection(DAI)和Dynamic ARP Inspection(DAI),可以帮助验证ARP应答的有效性。
- 网络分段: 通过VLAN等手段将网络分割成更小的部分,限制ARP欺骗的影响范围。
3、DHCP snooping 技术
通过 DHCP Snooping 来控制 DHCP 请求跟应答报文的交互,防止仿冒的 DHCP 服务器为 DHCPClient 分配 IP 地址以及其他配置信息。
1、全局使能 DHCP Snooping 业务
[HUAWEI] dhep enable
[HUAWEI] dhep snooping enable
2、用户侧端口配置 DHCP Snoopn 能,DHCP Snooping 也可以在 VLAN 内配置,可以根据需要进行选择。
[HUAWEI] interface GigabitEthemet 8/0/1
[HUAWEI-GigabiEthemet8/0/1] dhep snooping enable
3、连接 DHCP 服务器的端口配置成信任端口
[HUAWEI] interface GigabitEthermnet 8/0/10
[HUAWEI-GigabitEthem et8/0/10] dhcp snooping trusted
4、Dos/DDos 攻击
拒绝服务攻击名称 说明
SYN Flood 攻击 利用 TCP 三次握手的一个漏洞向目标计算机发动攻击。攻击者向目标计算机发送 TCP 连接请求(SYN 报文),然后对于目标返回的 SYN-ACK 报文不作回应。目标计算机如果没有收到攻击者的 ACK 回应,就会一直等待,形成半连接,直到连接超时才释放。攻击者利用这种方式发送大量 TCP SYN 报文,让目标计算机上生成大量的半连接,迫使其大量资源浪费在这些半连接上。目标计算机一旦资源耗尽,就会出现速度极慢、正常的用户不能接入等情况。攻击者还可以伪造 SYN 报文,其源地址是伪造的或者不存在的地址,向目标计算机发起攻击。
Ping os Death
网络设备对数据包的大小是有限制的,IP 报文的长度字段为 16 位,即 IP 报文的最大长度为 65535 字节。如果遇到大小超过 65535 字节的报文,会出现内存分配错误,从而使接收方死机。攻击者只需不断的通过 Ping 命令向攻击目标发送超过 65535 字节的报文,就可以使目标对象的 TCP/IP 堆栈崩溃,致使接收方死机。
Teardrop
攻击者获取 IP 数据包后,把偏移字段设置成不正确的值,接收端在收到这些分拆的数据包后,就不能按数据包中的偏移字段值正确组合出被拆分的数据包,这样,接收端会不停的尝试,以至操作系统因资源耗尽而崩溃。
smurf 攻击
攻击者向目标网络发送 ICMP 应答请求报文,该报文的目标地址设置为目标网络的广播地址,这样,目标网络的所有主机都对此 ICMP 应答请求作出答复,导致网络阻塞。Smurf 攻击
Smurf 攻击是一种分布式拒绝服务 (DDoS) 攻击的一种形式,它利用了 Internet 控制消息协议 (ICMP) 中的一个漏洞,该漏洞存在于早期的网络设备和操作系统中。这种攻击可以放大攻击者的网络流量,从而对目标主机造成严重的带宽消耗和服务中断。
攻击原理
放大效果:因为每个主机都会向受害者发送响应,这实际上产生了放大效果。例如,如果攻击者发送了一个 60 字节的 ICMP 请求,而每个响应的平均大小是 200 字节,那么如果有 100 台主机响应,则会产生大约 20,000 字节的流量,远远超过原始请求的大小。
伪造 ICMP 回显请求(Ping 请求):攻击者向一个或多个中间网络(通常是大型网络,如 ISP 网络)中的广播地址发送伪造的 ICMP 回显请求(即 ping 请求)。这些请求的源 IP 地址被篡改,使之看起来像是来自目标受害者的 IP 地址。
广播回显响应:中间网络中的每台主机都会响应这个广播请求,向被篡改的源 IP 地址(实际上是受害者)发送 ICMP 回显响应。
Winunuke
利用了 Windows 操作系统的一个漏洞,向这个 139 端口发送一些携带 TCP 带外(OOB)数据报文,但这些攻击报文与正常携带 OOB 数据报文不同的是,其字段与数据的实际位置不符,即存在重叠,Windows 操作系统在处理这些数据的时候,就会崩溃。
5、防DDOS 攻击 (无法彻底根治)
1.拒绝服务攻击(DoS攻击)和分布式拒绝服务攻击(DDoS攻击)的区别在于攻击者的数量和方式。 2.DoS攻击由单个攻击者发起,通过大量虚假请求耗尽目标系统的资源。 3.DDoS攻击由多个攻击者协同发起,利用大量肉鸡联合发起攻击,成倍提高攻击规模。 4.防范拒绝服务攻击的措施包括部署防火墙、IPS入侵防御系统、CDN内容分发网络等。 5.CDN技术通过分散攻击流量和降低主服务器的压力,提高网络的防御能力和恢复速度。
抗 DDoS 设备 防火墙、IPS
. 部署内容分发网络 CDN
购买流量清洗服务或流量清洗设备
・网站防护系统 WAF,WAF 防护应用层流量的拒绝服务攻击,适合防御 HTTP Get 攻击等。注意:WAF 服务并不提供针对四层及以下流量的防护,例如:ACK Flood、UDP Flood 等攻击,这类攻击建议使用 DDoS 及 IP 高防服务进行防护。
・网络架构上做好优化,采用负载均衡分流。
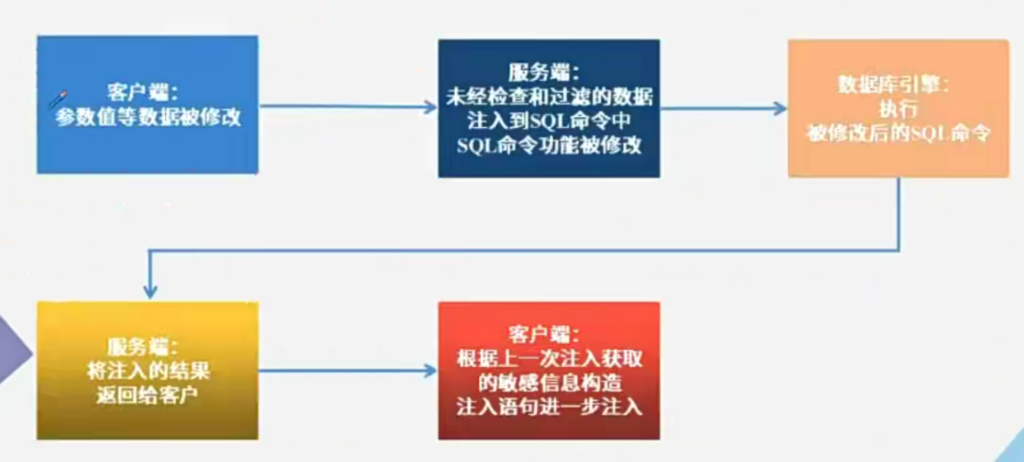
6、SQL注入

7、跨站脚本攻击
跨站脚本攻击(Cross Site Scripting) 其原理是攻击者向有 XSS 漏洞的网站中输入(传入)恶意的 HTML 代码,当其他用户浏览该网站时,这段 HTML 代码会自动执行,从而达到攻击的目的。如,盗取用户 Cookie、破坏页面结构、重定向到其他网站等。
XSS 防御
・验证所有输入数据,有效检测攻击。
对所有输出数据进行适当的编码,以防止任何已成功注入的脚本在浏览器端运行。 部署WAF、IPS 等专业设备。