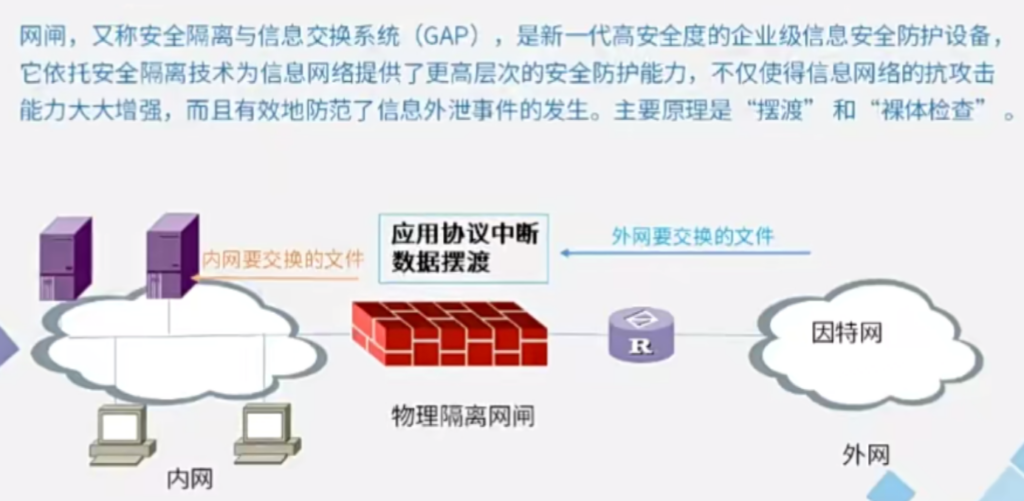
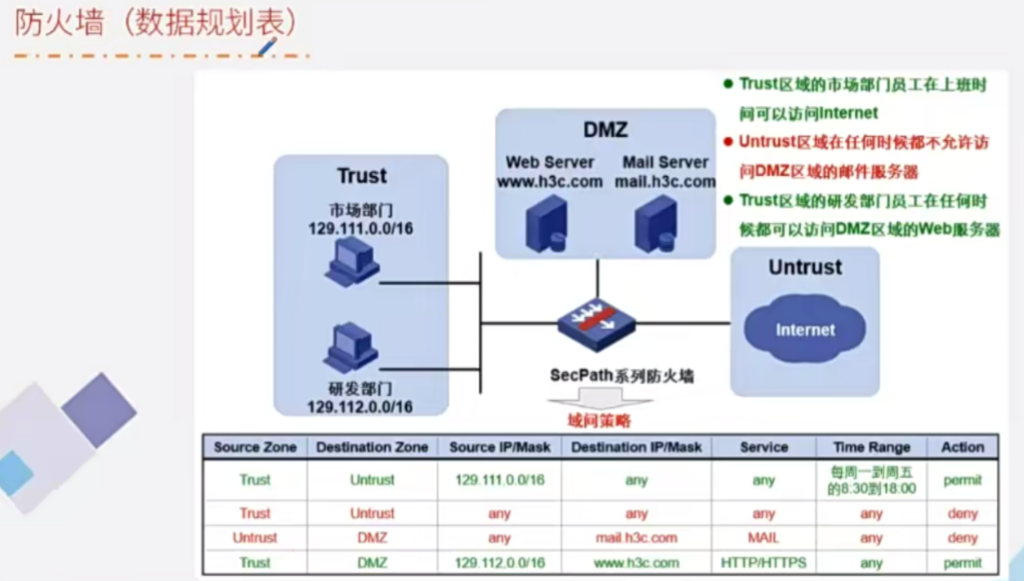
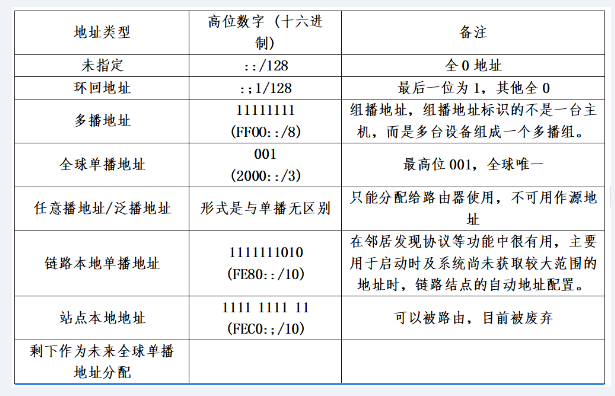
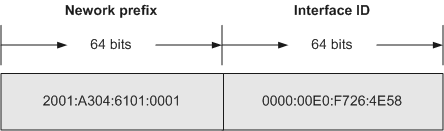
1、AI芯片架构
AI 芯片架构是专门为人工智能应用设计的硬件架构。
常见的 AI 芯片架构包括以下几种类型:
- 通用图形处理单元(GPGPU)架构:基于传统的图形处理单元进行优化,具有大量的并行计算核心,适用于大规模数据的并行处理。
- 张量处理单元(TPU)架构:专为深度学习中的张量运算而设计,具有高效的矩阵乘法单元和低功耗的特点。
- 现场可编程门阵列(FPGA)架构:具有可编程性,可根据具体的应用需求进行灵活配置。
- 专用集成电路(ASIC)架构:为特定的人工智能任务定制设计,具有高性能和低功耗的优势,但开发成本较高。
2、数据库模式
在数据库领域,数据库的模式(Schema)是指数据库中数据的结构化定义,它定义了数据库中各种对象的组织方式,包括表、视图、索引、键、数据类型等。模式可以分为三个主要层次:外模式(External Schema)、概念模式(Conceptual Schema)和内模式(Internal Schema)。这三个层次共同构成了数据库的三级模式体系结构。
- 外模式(External Schema):
- 定义:外模式也称为子模式或用户模式,它是用户看到的数据视图。每个用户或应用程序可能有自己的外模式,它定义了用户可以访问的那些数据的结构。
- 特点:外模式是数据库用户视图的局部逻辑结构,可以对应一个或多个表的部分内容。
- 用途:外模式用于简化用户的操作,让用户不必关心数据库的整体结构,只需要知道如何使用自己的数据。
- 概念模式(Conceptual Schema):
- 定义:概念模式也称为逻辑模式,它是数据库中全部数据的全局逻辑视图。它定义了数据库中所有数据的逻辑结构、数据类型、数据之间的关系等。
- 特点:概念模式描述了数据库的整体结构,是所有外模式的集合。
- 用途:概念模式用于确保数据的一致性和完整性,是数据库管理员(DBA)的主要关注点。
- 内模式(Internal Schema):
- 定义:内模式也称为物理模式或存储模式,它描述了数据在物理存储介质上的存储方式,包括存储结构、存储方法、存取路径等。
- 特点:内模式涉及数据的实际物理存储细节,如数据块的大小、存储位置、索引类型等。
- 用途:内模式主要用于优化数据存储和检索,提高数据访问效率,通常由数据库管理系统(DBMS)自动管理。
三级模式体系结构的作用
- 数据独立性:三级模式体系结构的设计目的是为了实现数据独立性,即数据的物理结构变化不会影响逻辑结构,逻辑结构的变化也不会影响用户视图。
- 简化用户操作:通过外模式,用户只需关注自己关心的数据部分,而无需了解整个数据库的复杂结构。
- 增强数据一致性:概念模式确保数据的一致性和完整性,防止数据冗余和异常。
这些模式之间的映射关系(外模式到概念模式、概念模式到内模式)是由数据库管理系统(DBMS)维护的,用户通常不需要直接操作这些映射。
3、鸿蒙操作系统
鸿蒙操作系统是基于 Lnux 系统来开发操作系统的。两大好处在于一是可以很好地兼安卓系统的 APP,毕竟安卓系统是基于 Linu 系统来进行开发的。另一方面鸿蒙是一个集计算机,手机,汽车等设备于 一体的大一统的系统。鸿蒙系统道从分层设计,从下向上依次为内核层,系统服务层,框架层和应用层 内核层 内核层由鸿蒙微内核,Linux 内核,LiteOS 组成,未来将发展为完全的鸿微内核架构。采用多内核设计,支持针对不同资源受设备选用不同的 OS 内核。 系统服务层 是鸿蒙的核心能力集合,通过框架层对应用程序提供服务。它是系统基本能力子系统集,基础软件服务子系统集,增强软件服务子系统集,硬件服务子系统集。 框架层 应用程序提供了 JavaCC++ JS 等多语言的用户程序框架和 Abity 框架 应用层 应用层包括系统应用和第三方非系统应用。鸿蒙的应用由一个多个 FA (Feature Abilit) PA (Particle blity。其中 FA 有界面,其供与用户交互的能力,而PA则无界面,提供后代运行任务 的能力及统一的数据访问抽象。
4、软件著作权
自软件开发完成之日起,著作权就完成就产生了。所以享有著作的时间是作品完成时。作品完成后如会发表、发布,么这个时间就是发表日期。但是如果去版权登记机构登记,那么取得版权登 证书的时间就是证书发证日期。
5、存储器
RAM(随机存储器)的种类主要有以下两种:
- 静态随机存储器(SRAM):
- 速度快,不需要刷新电路就能保存数据。
- 集成度较低,功耗较大,成本较高。
- 常用于高速缓存(Cache)。
- 动态随机存储器(DRAM):
- 集成度高,功耗较低,成本相对较低。
- 需要定时刷新电路来保持数据。
- 是计算机主存的常用类型。
ROM(只读存储器)的种类主要包括:
- 掩膜 ROM:
- 由生产厂家在制造时写入信息,用户无法更改。
- 可编程只读存储器(PROM):
- 用户可以一次性写入信息,但写入后无法修改。
- 可擦除可编程只读存储器(EPROM):
- 可以用紫外线擦除信息,然后重新编程。
- 电可擦除可编程只读存储器(EEPROM):
- 可以通过电信号进行擦除和重新编程。
6、文件类型
在操作系统中,不同的文件类型对于系统的稳定性和数据完整性有着不同的影响。当系统在写回磁盘的过程中突然掉电,不同类型的文件受到影响的程度也会有所不同。下面是对选项A到D的分析:
A. 目录(Directory)
- 影响程度:高
- 原因:目录包含了文件系统的结构信息,包括文件的位置、权限等元数据。如果在更新目录时系统掉电,可能会导致文件系统结构混乱,进而影响到文件的访问和管理。例如,一个文件可能被标记为不存在,或者两个文件可能被错误地认为位于同一位置。
B. 空闲块(Free Blocks)
- 影响程度:较低
- 原因:空闲块记录的是未被使用的磁盘空间。虽然空闲块的信息对于磁盘空间管理很重要,但如果在更新空闲块列表时掉电,可以通过文件系统的检查和修复工具来恢复这些信息,不会导致数据丢失。
C. 用户程序(User Program)
- 影响程度:低
- 原因:用户程序通常是可执行文件,一旦安装完成就很少改变。即使在更新用户程序时掉电,最坏的情况也只是该程序损坏,可以通过重新安装来解决,不会影响其他部分的系统功能。
D. 用户数据(User Data)
- 影响程度:较高
- 原因:用户数据是指用户创建的文件和数据,如文档、图片等。虽然用户数据的丢失或损坏会影响用户的体验,但通常可以通过备份和恢复机制来减轻这种影响。对于单个用户来说,这可能是一个严重的损失,但对于整个系统的稳定性来说,影响相对较小。
7、编译器和解释器
编译器和解释器都是编程语言处理程序,它们的主要作用是将程序员编写的源代码转换成计算机可以直接执行的形式。尽管它们的目标相似,但在工作方式上存在显著差异。下面是编译器和解释器的主要特点:
编译器 (Compiler)
- 一次性转换:
- 编译器将整个源代码一次性转换成目标代码(通常是机器代码或字节码),然后再执行。
- 编译过程通常发生在程序运行之前。
- 生成可执行文件:
- 编译器通常会生成一个可执行文件或库文件,可以直接在目标平台上运行,无需额外的编译步骤。
- 执行速度:
- 由于编译后的代码通常是针对特定硬件优化过的机器码,因此执行速度较快。
- 错误检测:
- 编译器会在编译过程中检测语法错误和类型错误,并在编译阶段给出错误信息。
- 独立执行:
- 编译后的程序可以独立运行,不需要编译器本身的支持。
可移植性
- 平台相关性:
- 编译后的代码通常是针对特定架构(例如 x86 或 ARM)的,这意味着如果要在不同的硬件平台上运行,可能需要重新编译。
- 不同的操作系统也可能需要不同的编译选项或库文件。
- 跨平台编译:
- 有些编译器支持交叉编译,即在一个平台上编译出另一个平台的可执行文件。
- 使用像 LLVM 这样的工具链可以提高代码的可移植性,因为它可以在多种平台上生成代码。
解释器 (Interpreter)
- 逐行解释:
- 解释器直接读取源代码,并逐行解释执行,而不是先将其转换成目标代码。
- 解释过程与程序的执行过程同步进行。
- 动态执行:
- 解释器允许程序在运行时动态修改和扩展,适用于需要频繁更改代码的场合。
- 执行速度:
- 由于解释器在运行时逐行解释代码,因此执行速度通常比编译后的程序慢。
- 错误检测:
- 解释器在执行代码时会检测错误,因此错误通常在运行时出现。
- 依赖解释器:
- 使用解释器的语言需要解释器在目标系统上可用才能运行。
示例
- 编译型语言:C, C++, Rust
- 解释型语言:Python, Ruby, JavaScript (在浏览器中通常由JavaScript引擎解释执行)
总结
- 编译器:一次性将源代码转换为目标代码,生成可执行文件,执行速度快,适合大型项目或对性能要求较高的应用。
- 解释器:逐行解释源代码,适合快速开发和测试,便于调试和修改,适合脚本语言或小型项目。
可移植性
- 平台无关性:
- 解释器通常不关心底层硬件细节,这使得源代码更容易在不同平台上运行,只要目标平台上安装了解释器即可。
- 源代码可以几乎不变地在多个操作系统和架构之间移植。
- 即时编译 (JIT):
- 许多现代解释器采用 JIT 编译技术,在运行时将代码编译成本地机器码,这可以提高执行效率同时保持良好的可移植性。
8、光纤损耗计算(以多少千米每分贝计算)
光纤信号经 10km 线路传输后光功率下降到输入功率的 50%, 只考虑光纤线路的衰减,则该光纤的损耗系数为
首先,光功率下降到输入功率的 50%,即衰减了 50%。
根据损耗系数的定义:损耗系数 = -(10×lg(输出功率 / 输入功率))÷ 传输距离
已知传输距离为 10km,输出功率为输入功率的 50%,即 0.5 倍输入功率。
光损耗系数 = -(10×lg(0.5))÷ 10 ≈ 0.3 dB/km

光纤通信中的损耗系统计算通常涉及几个关键因素,包括光纤本身的损耗、连接器损耗、接头损耗以及弯曲损耗等。这些因素共同决定了信号从发送端到接收端的整体损耗水平。
光纤损耗系统的计算公式

计算示例
假设您有一段长度为 10km 的单模光纤,光纤本身的损耗为 0.2 dB/km;两端各有一个连接器,每个连接器的损耗为 0.5 dB;中间有一个接头,其损耗为 0.1 dB;光纤的弯曲损耗为 0.2 dB(假设在整个链路中有轻微的弯曲)。
则总损耗 Ltotal可以这样计算:
Ltotal=(10×0.2)+(2×0.5)+0.1+0.2=2+1+0.1+0.2=3.3 dB
这意味着从发送端到接收端的总损耗为 3.3 dB。