BGP 采用tcp 发现和维护邻居的机制应该是怎样的?
一:TCP面向连接,基于TCP的协议必然有一个先建立连接的过程。要先建立连接,两端的设备就必须先互相知道对方的IP地址,并且路由可达。那么是采用静态配置的方式,还是动态建立连接的方式呢?BGP采用的是静态配置的方式,只要双方指定的地址路由可达,就可以建立连接。这样做有以下好处:
1:可以与对端设备用任何IP地址建立邻居,而不限于某个固定接口的IP。这样,我们就可以采用环回地址而非直连接口地址建立BGP邻居,两台设备之间如果主链路中断了,只要有备份链路存在,就可以把流量切换到备份链路上,保持邻居不断,增加了BGP连接的稳定性。
2:可以跨越多台设备建立邻居。由于是静态配置的方式,不一定只有直连设备才能建立BGP邻居,只要双方指定的地址路由可达(通过IGP或者静态路由),就可以建立邻居,这在AS内部建立IBGP连接时,就不用所有设备之间都建立IBGP连接。IBGP会在本期后面内容中提及。
二:知道对方IP地址后,BGP会通过发送open 报文来进行邻居的建立 。如果连接不能建立,说明对端设备状态不正常,于是会等待一段时间再进行连接的建立,这个过程一直重复,直到建立连接。
三:连接建立后,就可以进行路由表的同步了,BGP通过发送update 报文进行路由表的同步 。
四:路由表同步完成后,并不是马上拆除这个连接,因为随时有可能会有路由的更新或者删除,建立TCP连接是一个非常耗费资源的过程,所以BGP通过定期发送keepalive 报文进行TCP连接的维持,这样就可以不用重新建立连接,立刻就可以进行路由更新 。
五:如果经过一段时间(一般是3个keepalive 报文发送周期 keepalive 消息发送间隔为60秒)还没有收到对方的keepalive 报文时,我们就认为对方出现了问题,于是可以拆除该TCP连接,并且把从对方收到的路由全部删除 。(一定要在180秒之内收到keepalive 报文,保持对等体peer之间的连接)
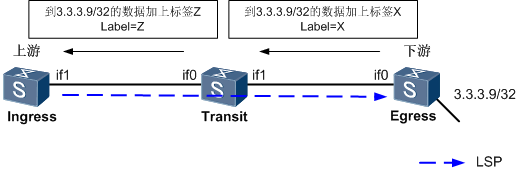
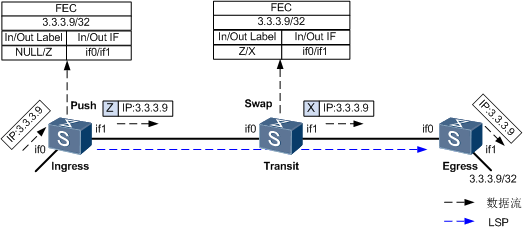
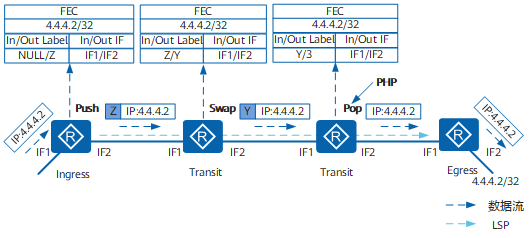
IGP 协议要求需要建立邻居关系的两台路由器必须是直连 的,然而 BGP 则大不相同。 BGP 的对等体关系并不要求设备必须直连 , BGP 采用 TCP 作为传输层协议,两台路由器只要具备 IP 连通性,并且能够顺利地基于 TCP1 79 端口建立连接,就可以建立 BGP 对等体关系,因此 BGP 对等体关系是可以跨设备建立的。
默认情况下,EBGP 邻居之间在发送BGP 报文时,TTL值为1,所以EBGP默认要求邻居之间必须物理直连。当使用环回接口建立EBGP邻居时,由于使用的不是物理直连接口,所以TTL会被多减1次成为0 ,最终BGP报文会被丢弃,从而导致邻居关系建立 失败,可以修改EBGP邻居发送BGP报文的TTL值,使用报文的TTL值大于1 。使用peer 1.1.1.1 ebgp-max-hop 2 命令。在实际场景中使用Loopback 建立 IBGP ,使用直连接口建立EBGP邻居关系 。
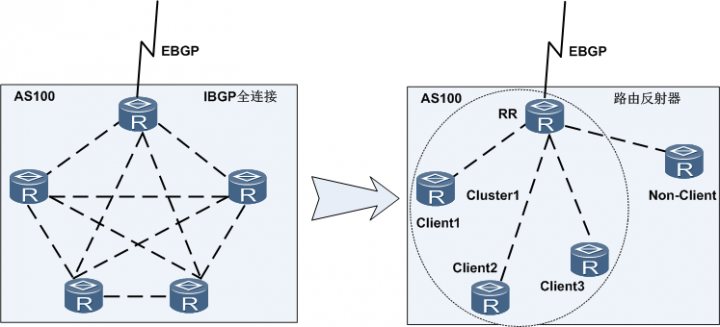
联盟(confederation )和路由反射器(Route Reflector )
BGP 联盟与路由反射器概念:解决逻辑(物理)全链接IBGP 数量过多的问题
BGP 不同IGP(OSPF、ISIS、RIP都是基于UDP)
每种路由协议的防环 机制是什么:
而BGP是距离矢量协议,就是A->B->C-A 之间形成一个环路。
IBGP 路由反射器应用示例 路由反射器的思想:指定其中一台设备可以转发从IBGP对等体收到的路由,则其他设备只需要和该设备建立IBGP连接,就可以保证路由能够传递到所有的设备上。这就是路由反射器的思想。
路由反射器RR的一些概念:
路由反射器RR(Route Reflector):允许把从IBGP对等体学到的路由反射到其他IBGP对等体的BGP设备,类似OSPF网络中的DR。
客户机(Client):与RR形成反射邻居关系的IBGP设备。在AS内部客户机只需要与RR直连 。
非客户机(Non-Client):既不是RR也不是客户机的IBGP设备。在AS内部所有非客户机与所有RR之间仍然必须建立全连接关系。
始发者(Originator):在AS内部始发路由的设备。Originator_ID属性用于防止集群内产生路由环路。这点会在后面详细介绍。
集群(Cluster):路由反射器及其客户机的集合 。Cluster_List属性用于防止集群间产生路由环路。这点会在后面详细介绍。
当一个集群里有多个路由反射器时 ,必须为同一个集群内的所有路由反射器配置相同的集群ID。
如果路由反射器的客户机之间重新建立了IBGP全连接关系,那么客户机之间的路由反射就是没有必要的,而且还占用带宽资源。此时可以配置禁止客户机之间的路由反射 ,减轻网络负担。
在一个AS内,RR主要有路由传递和流量转发两个作用 。当RR连接了很多客户机和非客户机时,同时进行路由传递和流量转发会使CPU资源消耗很大,影响路由传递的效率。如果需要保证路由传递的效率,可以在该RR上禁止BGP将优选的路由下发到IP路由表,使RR主要用来传递路由。
将BGP 路由器配置为RR
bgp 200
router-id x.x.x.x
peer 10.0.12.1 as-number 200
peer 10.0.23.1 as-number 200
#
ipv4-family unicast
undo synchronization (关闭同步是指IGP协议的同步)
reflector cluster-id 1 /配置cluster-id,缺省为设备router id,可选配置
peer 10.0.12.1 enable
peer 10.0.12.1 reflect-client /配置10.0.12.1为客户机
peer 10.0.23.1 enable
peer 10.0.23.1 reflect-client
在华为数据通产品上在RR 上对iBGP 增加一条reflect-client 参数就表示iBGP邻居是它的Client了。在Client上按照常规方式和RR建立 iBGP邻居。RR-Client关系只需要在RR上设定不要互相指定 。不要随意设计多级的RR-Client,就是R2是R3的RR, R3又是R4的RR.
BGP 网络中RR设计规范
iBGP传递路由只能传递一跳,而RR在反射路由的时候也只是多反射一跳,所以在RR-Client这个结构中,iBGP路由也最多反射两跳。
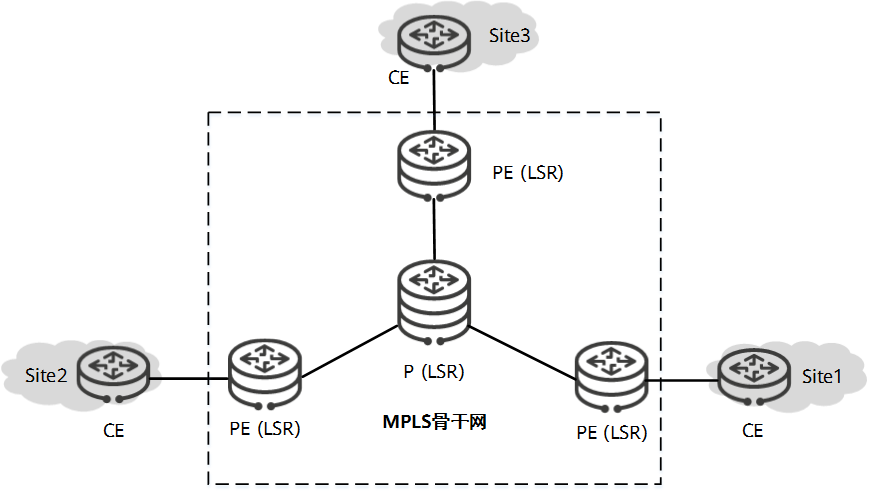
在骨干网络的设计中,只允许设计一级RR,其他的PE设备必须都和RR建立iBGP邻居关系。这就要求iBGP邻居都用Loopback 地址作为更新源,并且由IGP打通Loopback之间的路由。
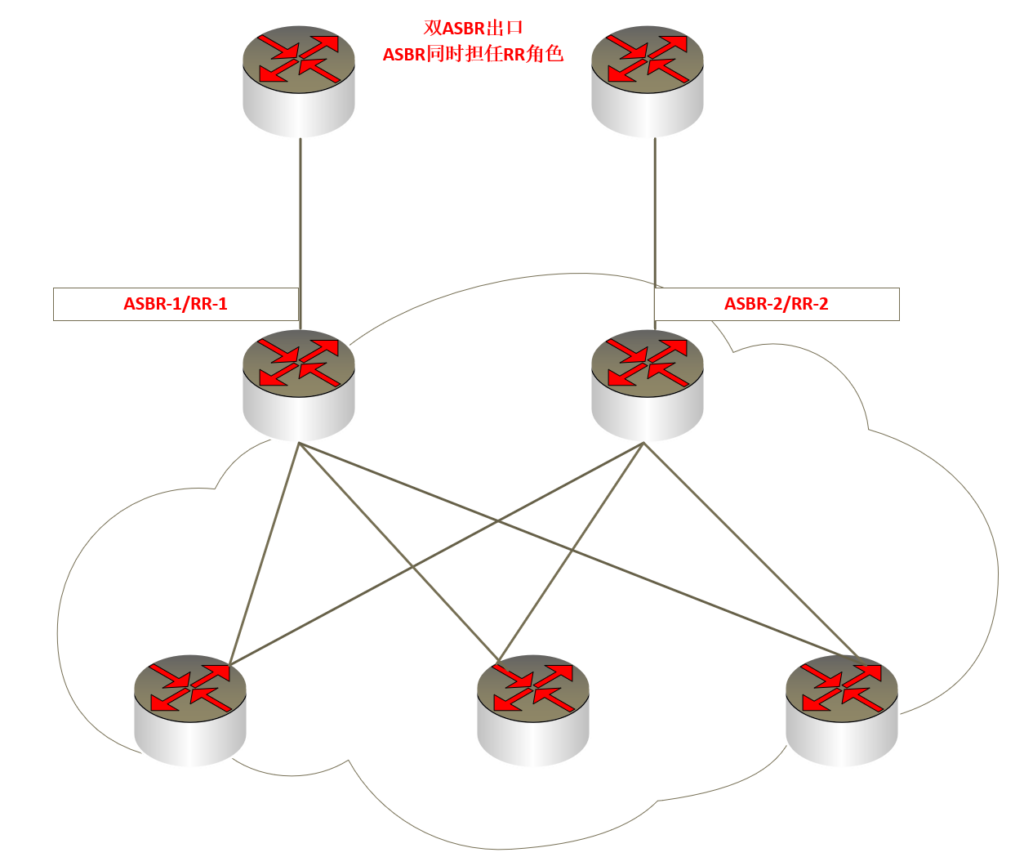
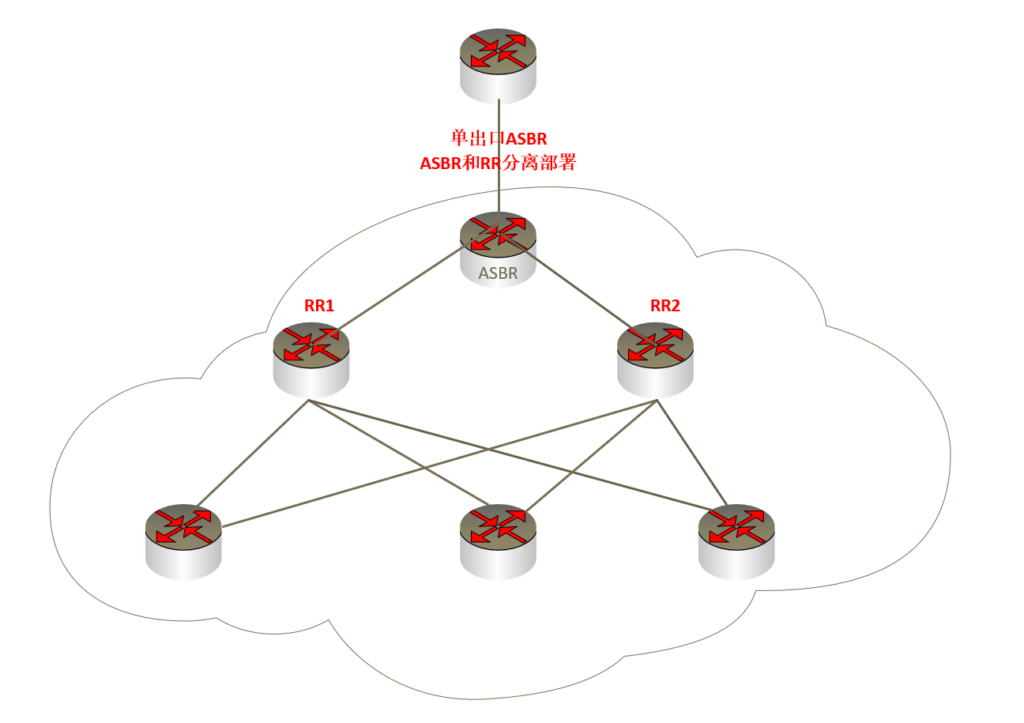
为了保证RR的冗余性,一般在骨干网AS内部都会设置两个RR。再综合考虑网络规模,设备性能等因素,决定ASBR是否同时担任RR的角色。
ASBR 和 RR
RR是负责AS内外路由汇聚的,偶尔也能担负路由选路和路由过滤的功能,且RR也担负着和AS内所有BGP路由器建立iBGP邻居的任务,所以它们在网络中的位置非常重要。
ASBR 和 RR 的几种部署模式:
在2个ASBR同时担任RR 角色时,2个RR 必须建立iBGP邻居关系且互反射,其他BGP 设备也和2个RR 建立iBGP邻居关系,优点是方便配置选路,缺点是ASBR压力巨大只有2个ASBR的情况下,可以选择这种结构。
在只有一个ASBR的情况下,或者2个ASBR堆叠成一台设备时,可以考虑让RR和ASBR角色分离。但不管是什么情况,其他的BGP设备一定要和RR建立邻居关系,RR 之间也要建立邻居关系。这种拓扑下ASBR和RR 分离,设备压力较轻。缺点是BGP选路和设置相对麻烦一些。
BGP 对等体组
在大型BGP网路中,对等体的数目众多,配置和维护极为不便。对于存在相同配置的BGP对等体,可以将它们加入一个BGP对等体组进行批量配置,简化管理的难度,并提高路由发布效率。
对单个对等体和对等体组同时配置了某个功能时,对单个对等体的配置优先生效。
当使用Loopback接口或子接口的IP地址建立BGP连接时,建议对等体两端同时配置步骤6,以保证两端连接的正确性。如果仅有一端配置该命令,可能导致BGP连接建立失败。
当使用Loopback接口建立EBGP连接时,必须配置步骤7(其中hop-count ≥2),否则EBGP连接将无法建立。
操作步骤
执行命令system-view
执行命令bgp as-number-plain | as-number-dot },进入BGP视图。
执行命令group group-name [ external | internal ],创建对等体组 。
执行命令peer group-name as-number { as-number-plain | as-number-dot },配置EBGP对等体组的AS号。
执行命令peer ipv4-address | ipv6-address } group group-name ,向对等体组中加入对等体。
(可选)执行命令peer group-name connect-interface interface-typeinterface-number [ ipv4-source-address ]或者peer group-name connect-interface interface-typeinterface-number [ ipv6-source-address ] ,指定BGP对等体之间建立TCP连接会话的源接口和源地址。缺省情况下,BGP使用报文的出接口作为BGP报文的源接口。
(可选)执行命令peer group-name ebgp-max-hop [ hop-count ],指定建立EBGP连接允许的最大跳数。缺省情况下,只能在物理直连链路上建立EBGP连接,EBGP连接允许的最大跳数为1。
(可选)执行命令peer group-name description description-text ,配置对等体组的描述信息。
可选)请根据实际网络选择以下命令。
执行命令peer group-name enable ,为原有的BGP对等体组使能MP-BGP功能,成为MP-BGP对等体组。
如果在IPv4单播网络中配置BGP对等体组,不需要执行步骤9和步骤10。如果在IPv4组播和IPv6单播网络中配置BGP对等体组,需要执行步骤9和步骤10。
IBGP和EBGP 防环机制
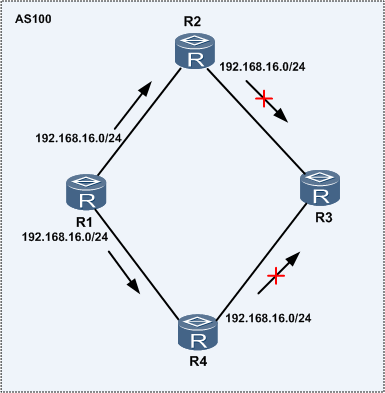
EBGP的防环机制是添加AS-PATH 属性,IBGP 是使用距离矢量协议的“水平分割”机制防止环路。
IBGP 防环机制是水平分割:从IBGP对等体接收到的路由不会通告给其他的IBGP邻居。路由只能传递一跳。
即:R2,R4接受到R1的192.168.16.0/24 的路由不会再通告给R3。
R3想学习到192.168.16.0/24的路由必须和R1连接。所以必须在4台路由器之间建立IBGP的全连接的关系,
由于IBGP 内部路由只能传递一跳,所以要想IBGP 邻居获得对端AS 传递过来的路由就需要所有设备和ASBR 建立邻居关系 。Full Mesh iBGP
BGP的属性:我们把添加在BGP路由中,为了解决某些问题的数据称为属性。 如上文解决EBGP环路问题所引入的数值(AS号),就是我们目前第一次引入的属性的概念,我们称之为AS_PATH属性。在BGP中,属性是一个非常重要的概念,因为BGP相较IGP非常大的一个优势就是可以在路由中携带丰富的属性,这些属性可以帮助我们对路由进行控制。 BGP里规定, AS_PATH属性较短的路由,将会被优选。可以手动修改AS_PATH属性。
路径属性
BGP神功之精髓,在于“属性”二字,此出入方向流量的路径控制,也落在这“属性”二字上了。”
LOCAL_PRAF属性
(以下简称LP本地优先级)和(MULTI_EXIT_DISC 出口鉴别)器属性 (以下简称MED)是BGP协议在控制AS出口流量路径时经常用到的两个属性。
MED :
当一个运行BGP的设备通过不同的EBGP对等体得到目的地址相同但下一跳不同的多条路由时,在其它条件相同的情况下,将优先选择MED值较小者作为最佳路由。
LP属性被用于在去往同一目的地的多条路由中设置路由优先级, 从名字就可以看出,LP属性只是应用于本地对等体之间,即只能在IBGP对等体之间传递,不会应用于EBGP对等体之间 。LP属性常用于AS出口出方向流量的路径控制,LP属性值越大,路由越优。
通常情况下,MED属性的作用是在去往邻居AS存在多条链路时,允许AS为入站流量传达其优先级 。(一般来说,比较不同AS的MED属性没有太大意义,特殊场景除外。)从MED属性的作用可以看出,MED属性只是作用于EBGP对等体,而IBGP对等体互相通告路由时,会忽略MED属性。MED属性常用于AS出口入方向流量的路径控制,MED属性值越小,路由越优 。
MED只会影响相邻两个AS,收到MED属性的AS不会把此属性再继续传递给别的AS。
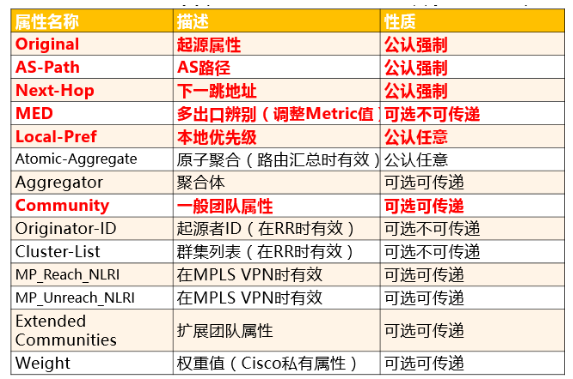
BGP的路径属性列表及分类(标红加粗字体的为常用属性,需要重点了解):
成为BGP的路由有两种方式,一种用network命令发布到BGP路由表中,一种是从IGP路由表中重分发进BGP。使用network命令发布到BGP路由表的,起源属性为“i”;重分发进BGP的路由,起源属性为“?”,读作:imcomplete。
AS_Path :中包含了BGP路由器到达目的地所经过的所有AS号码的集合,如果这条路由是从iBGP传来,则AS-Path属性不显示。而BGP在针对AS-Path执行路径选择的时候,总会选择“AS-Path最短”,也就是包含AS号码最少的路径。这样的话,可能造成BGP选出的“最优路径”实际上是最差的路径 。
Next-Top 属性:就是下一跳地址属性。但是,BGP的下一跳地址和IGP的下一跳地址是有一定的区别的。IGP也就是我们说的静态路由、OSPF、EIGRP这些路由,它的下一跳地址默认是:“直连设备的互联接口地址”
而BGP的Next-Hop属性却有一定的区别,它是这么定义的:
1、如果是本地始发的路由,则Next-Hop为0.0.0.0,一定会被优选;
如果一条路由从iBGP邻居学习而来,而iBGP邻居的更新源地址通常是Loopback接口地址 ,则iBGP学习到的路由的Next-Hop属性也将是Loopback接口地址 。
Next-Hop 地址对当前设备不可达,则这条路由无效。
一个很重要的知识点,就是iBGP和eBGP针对Next-Hop属性的处理。
1、eBGP在传递路由给邻居时,默认会修改路由的Next-Hop属性为自身的更新源地址;
使用next-hop-local 修改下一跳地址。
当Next-Hop 下一跳在IBGP 中传递时不修改Next-hop属性会导致,同一AS内除建立EBGP 邻接关系之外的路由器无法到达Next-hop 地址。所以在AS内向IBGP邻居添加Next-hop-local 的原因了 ,强制IBGP在传递Next-hop下一跳时修改自身的源地址。执行命令peer ipv4-address | group-name | ipv6-address } next-hop-local ,配置BGP设备向IBGP对等体(组)发布路由时,把下一跳地址设为自身的IP地址。缺省情况下,BGP设备向IBGP对等体发布路由时,不修改下一跳地址 。
BGP 的更新源 IP 地址也即设备发送 BGP 协议报文时所使用的源 地址,该地
AS-PATH 属性
AS-PATH 属性是不能重复的,但AS号码是可以重复的,这也就表示可以往AS-Path属性中添加多个重复的AS号码,以加长非优选方向的AS-Path长度。
BGP 路由属性的比较顺序 BGP路由属性的比较顺序为Preferred Value属性,Local Preference属性,路由生成方式,AS_Path属性,Origin属性,MED属性,BGP对等体类型等。
BGP 更新源接口的使用
在iBGP 内部一般使用环回接口作为更新源,在EBGP之间一般使用物理接口作为更新源。
BGP 路由通告
BGP 路由在对等体之间交 时, 要存在以下几个原则:
当一台路由器发现了多条可到达同一个目的网段的 BGP 路由时,该路由器会通过一个路由选择进程在这些路由中选择一条最优 CBest) 的路由。通常情况下,路由器只将最优的路由加载到路由表中使用(激活了负载分担功能的情况除外),而且只会将最优的路由通告给 BGP 对等体。
当一台路由器从自己的 EBGP 体学习到 BGP 路由时,缺省时它会将这些路由通告给所有 IBGP 对等体及所有 EBGP 对等体。
当一台路由器从自己的 IBGP 对等体学习到 BGP 路由时,它不会将这些路由通告给其他 IBGP 对等体一-IBGP 的水平分割规则使然。
当一台路由器从自己的 IBGP 体学习到 BGP 路由时,如果 BGP 同步 被激活,则路由器只有从 IGP 协议也学习到相应的路由时,才会将这些 BGP 路由通告给 EBGP体:如果 BGP 同步被关闭,则即使没有从 IGP 协议学习到相应的路由,它也会将这些 BG 路由通告给 EBGP 对等体。
BGP 路由发布
使用network 发布路由的时候要确保这个路由在路由表中存在,且命令所指定的网段及掩码长度必须与路由表中对应的路由完全一致。