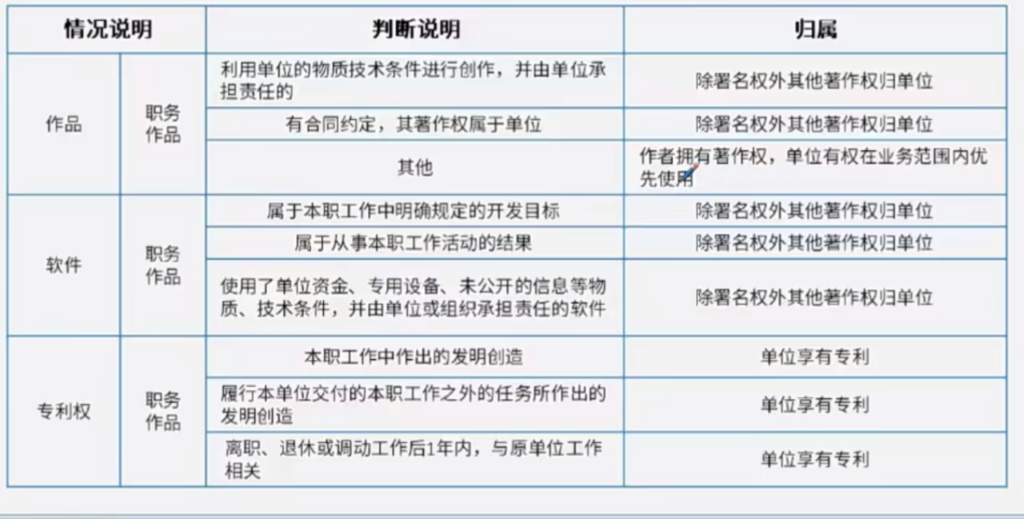
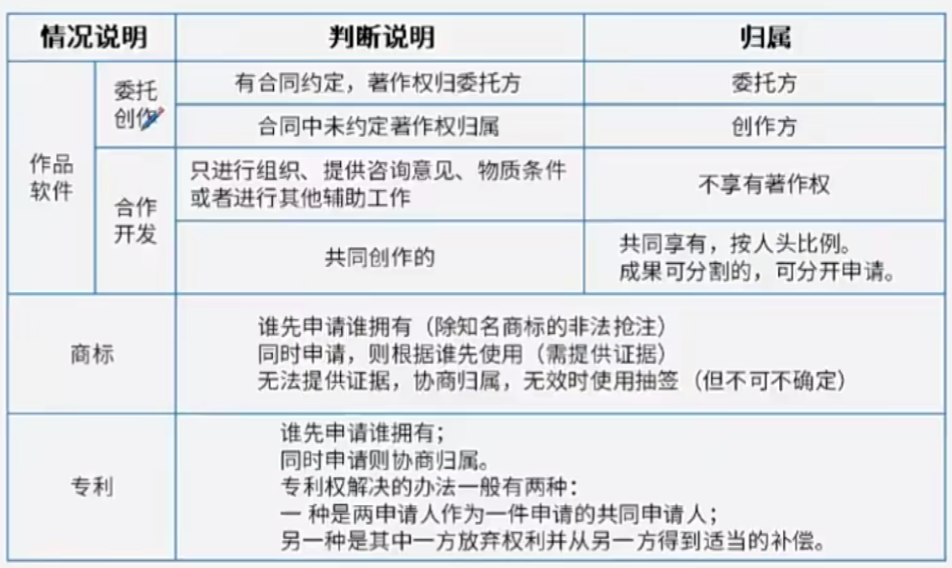
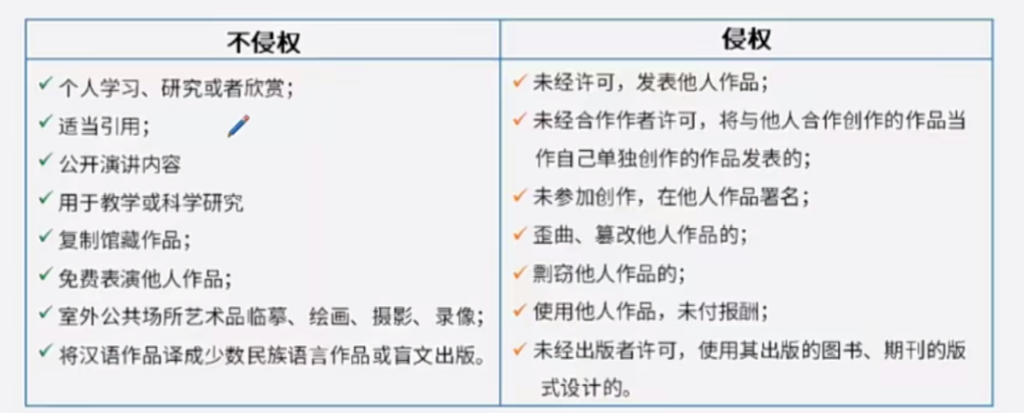
计算机流水线(pipeline)是一种处理器架构技术,通过将指令处理的不同阶段分割成一系列连续的步骤,使得处理器可以在同一时间内处理多条指令的不同部分。这种技术极大地提高了处理器的吞吐量和效率。
计算机流水线的基本概念
流水线阶段 :
计算机流水线通常被分为若干个阶段,每个阶段执行特定的任务。典型的流水线阶段包括:
取指(Fetch) :从内存中读取指令。译码(Decode) :解析指令的操作码和操作数。执行(Execute) :执行指令的操作。访存(Memory Access) :访问内存以读取或写入数据。写回(Write-back) :将执行结果写回到寄存器或内存中。
流水线的优点 :
更高的指令吞吐量 :通过并行处理多条指令的不同阶段,流水线可以显著提高处理器的性能。更短的平均指令执行时间 :即使单条指令的执行时间不变,由于流水线可以同时处理多条指令,整体的执行时间会缩短。
流水线的挑战 :
数据相关性 :如果一条指令依赖于另一条尚未完成的指令的结果,流水线就可能需要暂停,这种情况称为数据相关性(data dependency)或数据冒险(data hazard)。控制相关性 :分支指令可能导致流水线中的后续指令无效,因为它们可能不在正确的程序路径上执行。这种情况称为控制相关性(control dependency)或控制冒险(control hazard)。结构相关性 :如果硬件资源(如ALU、寄存器文件等)不足以支持流水线中的所有指令,就会发生结构相关性(structural dependency)或结构冒险(structural hazard)。
流水线的种类
静态流水线 :
在静态流水线中,流水线的各个阶段是固定的,且不受当前指令的影响。
这是最常见的流水线类型,通常用于现代处理器的设计。
动态流水线 :
动态流水线允许根据指令的特点动态调整流水线的阶段。
这种类型更为复杂,但在某些特殊情况下可以提供更好的性能。
流水线的应用
超标量处理器 :
超标量处理器结合了多个独立的流水线,能够在每个时钟周期内并行执行多条指令。
超标量与乱序执行 :
现代处理器通常结合了超标量技术和乱序执行,以进一步提高性能。
乱序执行允许处理器在遇到相关性时重新排列指令的执行顺序,从而绕过相关性带来的延迟。
示例
以一个简单的五级流水线为例:
IF(Instruction Fetch) :从内存中取出指令。ID(Instruction Decode) :解析指令。EX(Execute) :执行指令的操作。MEM(Memory Access) :访问内存。WB(Write Back) :将结果写回寄存器。
在这个例子中,假设处理器在每个时钟周期内可以完成一个阶段的工作,那么在理想情况下,处理器可以在每个时钟周期内开始处理一条新的指令。
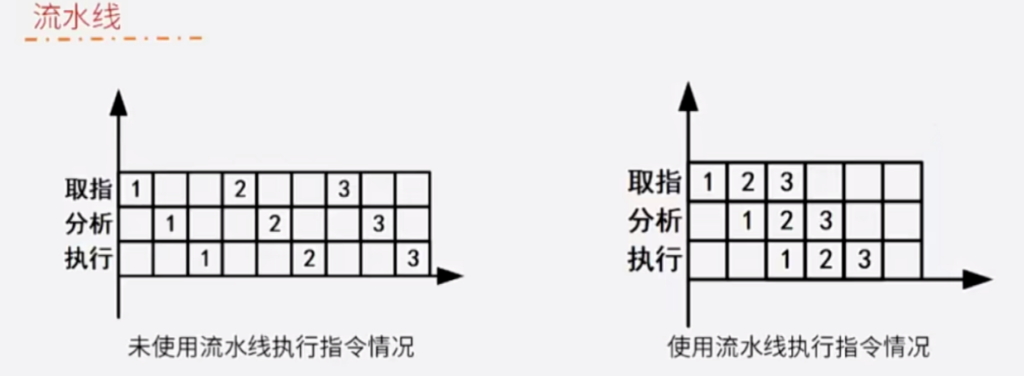
主要是根据时间轴去分析:第一条指令分析一秒执行一秒。你看第一条指令全部搞定,需要三秒钟,对不对?第二条指令同样三秒,第三条指令同样是三秒。所以是九秒钟,你才能够把三条指令全部执行到位。
在做分析第一条指令的时候,正好在取指第二条指令,对不对?两个是不是展开时间上的并行呢?可以缩短这个时间吧?你在取值第三条指令的时候,刚好在做第二条指令分析,刚好在做第一条指令的执行,是不是取得时间上的并行啊?这是典型的一种流水线技术。那么,省流水线执行指令的时间以三条指令为例。几秒钟啊,五秒钟是不是搞全部搞定了?是吧,五秒钟全部搞定了。
上图3条指令的 计算公式是Tk= 1+1+1+(3-1)*1 = 5 。 这里(3-1)为剩余的指令,*1 为每条指令部件中执行耗时最长的部件 ,这里都为1秒所以乘以1。
例子
某计算机系统采用5级流水线结构执行指令,设每条指令的执行由取指令(2Δt),分析指令(1Δt),取数操作(3Δt),运算(1Δt)和写回结果(2Δt)组成,并分别用5个子部件完成,该流水线的最大吞吐量(?);若连续向流水线输入10条指令,则该流水线的加速比为(?);
流水线周期:执行时间最长的那一段T。
指令执行总时间:各小段相加+(指令数-1)*最长那段(周期)
吞吐率:指令条数/指令执行总时间 、最大吞吐率为周期倒数1/T
加速比:采用串行模式时间与流水线模式时间的比值
为了回答您的问题,我们需要先理解流水线的工作原理,并计算出最大吞吐量以及连续输入10条指令时的加速比。
1. 最大吞吐量
首先,我们需要确定流水线中各阶段的时间。根据题目提供的信息,各阶段的时间分别为:
取指令 (IF): 2Δt
分析指令 (ID): 1Δt
取数操作 (MEM): 3Δt
运算 (EX): 1Δt
写回结果 (WB): 2Δt
在流水线中,最长的阶段决定了整个流水线的周期时间。在这个例子中,取数操作 (MEM) 阶段的时间最长,为3Δt,因此整个流水线的周期时间为3Δt。
最大吞吐量是指单位时间内流水线能完成的指令数量。在一个周期内,流水线可以处理一条完整的指令,因此最大吞吐量为:
2. 加速比
加速比是指非流水线方式执行一组指令所需的时间与流水线方式执行相同指令组所需的时间之比。为了计算加速比,我们需要知道两种情况下的执行时间。
非流水线方式
非流水线方式下,每条指令的总执行时间为所有阶段的时间之和:
总执行时间=2Δt+1Δt+3Δt+1Δt+2Δt=9Δt总执行时间=2Δt +1Δt +3Δt +1Δt +2Δt =9Δt
对于10条指令,总执行时间为:
总执行时间非流水线=10×9Δt=90Δt
流水线方式
在流水线方式下,第一条指令需要完整的9Δt时间来执行。之后的每条指令只需要流水线的周期时间3Δt即可完成。因此,对于10条指令,流水线方式下的总执行时间为:
第一条指令的执行时间为9Δt。
剩余9条指令的执行时间,每条指令3Δt,共9×3Δt = 27Δt。
总执行时间为:9Δt+27Δt=36Δt
计算加速比
结论
最大吞吐量 : 1/3Δt加速比 : 5/2 或者 2.5
这意味着,在最优情况下,该流水线的最大吞吐量为每3Δt执行一条指令,而连续输入10条指令时,流水线方式相比非流水线方式可以达到2.5倍的加速效果。
计算机的性能指标
计算机的主要技术性指标有主频、字长、内存容量、存取周期、运算速度及其他指标。
主频(时钟频率):是指计算机CPU在单位时间内输出的脉冲数。它在很大程度上决定了计算机的运行速度。单位MHz。
字长:是指计算机的运算部件能同时处理的二进制数据的位数。字长决定了计算机的运算精度。
内存容量:是指内存储器中能存贮的信息总字节数。能常以8个二进制位(bit)作为一个字节(Byte)。
存取周期:存储器连续二次独立的读或写操作所需的最短时间,单位纳秒(ns,1ns=10-9s)。存储器完成一次读或写操作所需的时间称为存储器的访问时间(或读写时间)。
运算速度:是个综合性的指标,单位MIPS(百万条指令/秒)。影响运算速度的因素,主要是主频和存取周期,字长和存储容量也有影响。
CPI(Clock cycle Per Instruction)表示每条计算机指令执行所需的时钟周期,通常用于衡量计算机性能;
MIPS(Million Instructions Per Second):每秒处理的百万级的机器语言指令数,也用于衡量计算机性能;
MFLOPS(Million Floating-point Operations per Second,每秒百万个浮点操作),衡量计算机系统的技术指标,不能反映整体情况,只能反映浮点运算情况。