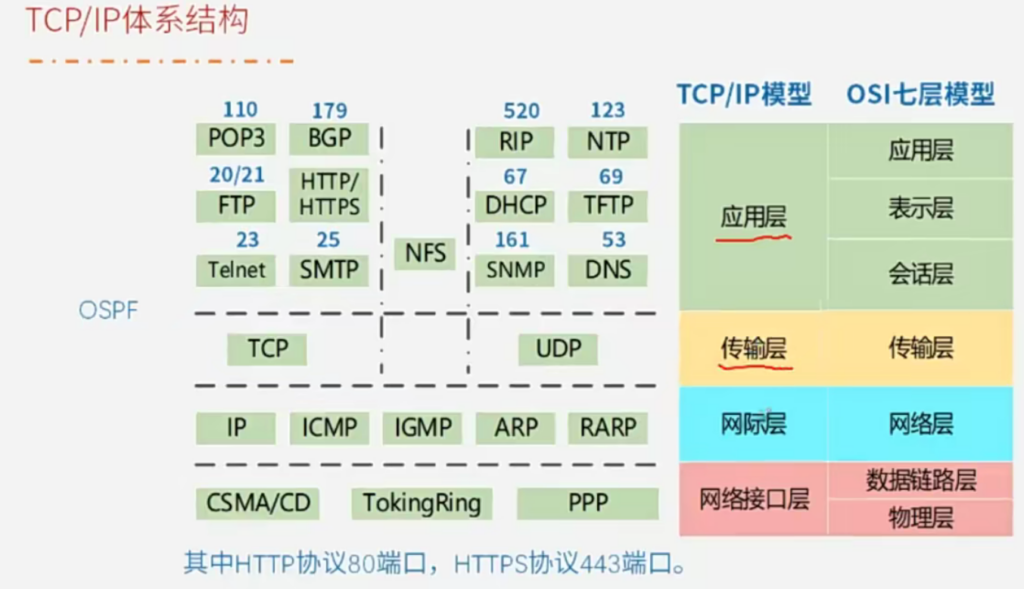
OSPF 属于应用层。
OSPF 属于应用层。
软件生命周期(Software Development Life Cycle, SDLC)是指从软件产品构思开始直到其不再使用的整个时间段内的一系列阶段。这些阶段覆盖了软件开发过程的所有方面,包括需求分析、设计、实现、测试、部署和维护等。
软件生命周期可以分为几个主要阶段:
每个组织可能会根据自己特定的需求和流程定制不同的软件生命周期模型,常见的模型有瀑布模型、迭代模型、敏捷开发模型等。
敏捷开发(Agile Development)是一种以用户需求进化为核心、迭代发布的开发方法。它的出现是为了应对传统瀑布模型中的一些不足之处,特别是当需求变化频繁时,瀑布模型难以适应。敏捷开发强调团队合作、客户协作、响应变化和快速交付。
敏捷开发的主要特点包括:
敏捷开发有许多不同的框架和实践,其中最著名的包括 Scrum、Kanban、XP(极限编程)、Crystal 等。每个框架都有自己独特的方法和实践,但它们都遵循敏捷宣言的原则:
| 性能测试的类型 |
| 性能测试类型包括负载测试、强度测试和容量测试等。 |
| (1)负载测试:负载测试是一种性能测试,指数据在超负荷环境中运行,程序是否能够承担。 |
| (2)强度测试:强度测试是在系统资源特别低的情况下考查软件系统运行情况。 |
| (3)容量测试:确定系统可处理的同时在线的最大用户数。 |
https://blog.csdn.net/lonelymanontheway/category_10805425.html
软件产品从形成概念开始,经过开发、使用和维护,直到最后退役的全过程,叫软件生存周期模型,又叫软件开发方法、软件开发模型(Software Develop Model)、软件过程模型 (Software Process Model)
大体来说,有3类:
又称快速原型模型,是快速建立起来的可以在计算上运行的程序,是软件的一个早期可运行的版本,它的功能是最终产品的子集。用途主要是获取用户的真正的需求。
原型模型主要有两个阶段:
特点:
阶段间具有顺序性和依赖性,前一阶段结束后才能开始后一阶段的工作,前一阶段的输出是后一阶段的输入;推迟实现观点,尽可能推迟程序的物理实现;强调质量保证观点,每个阶段必须完成规定的文档,每个阶段结束前完成文档以便及早改正错误。
瀑布模型可以说是最早使用的软件生存周期模型之一。由于这个模型描述软件生存的一些基本过程活动,所以它被称为软件生存周期模型。这些活动从一个阶段到另一个阶段逐次下降,形式上很像瀑布。瀑布模型的特点是因果关系紧密相连,前一个阶段工作的结果是后一个阶段工作的输入。
每一个阶段都是建立在前一个阶段的正确结果之上,前一个阶段的错误和疏漏会隐蔽地带入后一个阶段。这种错误有时甚至可能是灾难性的,因此每一个阶段工作完成后,都要进行审查和确认。
优点:
缺点:
也叫增量模型,其实质上是分段的线性模型,是一种非整体开发模型,渐增模型把软件产品作为一系列增量构件来设计、编码、集成和测试,在项目开发过程中以一系列的增量方式来逐步开发系统。
优点:
缺点:
适用场合:
螺旋模型是在结合瀑布模型与快速原型模型基础上演变而成,加入风险分析。
软考很恶心的地方在于抠字眼(单选题):
其基本思想,使用原型及其它方法来尽量降低风险。沿着螺线进行若干次迭代。两个显著特点:
形式化方法是一种具有坚实数学基础的方法,从而允许对系统和开发过程做严格处理和论证,适用于那些系统安全级别要求极高的软件的开发。
主要优越性:能够数学(精确)地表述和研究应用问题及软件实现。
但是它要求开发人员具备良好的数学基础。用形式化语言书写的大型应用问题的软件规格说明往往过于细节化,并且难以为用户和软件设计人员所理解。由于这些缺陷,形式化方法在目前的软件开发实践中并未得到普遍应用。
目标:尽可能早地、持续地对有价值的软件的交付
1.极限编程–XP
价值观:沟通、简单、反馈、勇气
原则:快速反馈,简单性假设,逐步修改,提倡更改和优质工作
2.水晶法(Crystal)
水晶法认为每个不同的项目都需要不通的策略、约定和方法论,认为人对软件质量有重要的影响,软件质量随开发人员素质的提高而提高
3.并列争求法(Scrum)
用迭代的方法,把每30天一次的迭代看做一次冲刺,并按需求的优先级来实现产品
配置库有三种:开发库、受控库、产品库。
信息系统项目完成后,最终产品或项目成果应置于产品库内,当需要在此基础上进行后续开发时,应将其转移到受控库后进行。
B2B:企业与企业之间通过互联网进行产品、服务及信息的交换
B2C:是指企业直接面向消费者提供商品或服务
G2E:指政府(Government)与政府公务员即政府雇员(Employee)之间的电子政务
G2B:是指政府(Government )与企业(Business)之间的电子政务
软件集成测试也称为组装测试、联合测试(对于子系统而言,则称为部件测试)。它将已通过单元测试的模块集成在一起,主要测试模块之间的协作性。从组装策略而言,可以分为一次性组装测试和增量式组装(包括自顶向下、自底向上及混合式)两种。集成测试计划通常是在软件概要设计阶段完成的,集成测试一般采用黑盒测试方法。一般来说:单元测试所对应的是详细设计环节;
集成测试对应概要设计;
系统测试,就是根据需求分析;验收测试与用户需求对应,是非设计流程。
软件文档是影响软件可维护性的决定因素。软件系统文档可以分为用户文档和(系统文档)两类。其中,用户文档主要描述(系统功能)和使用方法,并不关心这些功能是怎样实现的。
进程管理中的死锁是指两个或更多进程相互等待对方释放资源,从而导致所有进程都无法继续执行的情况。为了避免或解决死锁问题,操作系统通常采用预防、避免、检测和恢复等策略。
死锁的发生必须满足以下四个必要条件:
总结:系统中有N个并发进程,若规定每个进程需要申请R个某类资源,则当系统提供K=N*(R-1)+1个同类资源时,无论采用何种方式申请使用,一定不会发生死锁。
如果是3各进程请求2个资源时,则至少需要3*(2-1)+1 =4
处理死锁的策略通常包括预防、避免、检测和恢复四个方面:
假设我们有两个进程 P1 和 P2,它们分别需要获取资源 R1 和 R2。P1 先获取 R1,然后尝试获取 R2,而 P2 先获取 R2,然后尝试获取 R1。这样就形成了一个死锁环路。
进程的PV操作是用于同步进程间通信的一种机制,也称为信号量机制。PV操作是由荷兰计算机科学家Edsger W. Dijkstra提出的,其中P操作(Proberen,尝试)用于请求资源,V操作(Verhogen,增加)用于释放资源。PV操作主要用于解决进程间的同步问题,尤其是临界区问题。
信号量是一个整型变量,它用来表示资源的数量或状态。信号量的值可以是非负数,也可以是负数。信号量的值大于0表示资源可用,小于0表示等待资源的进程数量。
PV操作可以用于解决多种同步问题,包括但不限于:

下面是一个使用PV操作解决临界区问题的简单示例:
import threading
# 创建一个信号量
semaphore = threading.Semaphore(1)
def critical_section():
semaphore.acquire() # P操作
# 执行临界区代码
print(f"{threading.current_thread().name} is in the critical section.")
semaphore.release() # V操作
def process_function():
# 其他非临界区代码
critical_section()
# 其他非临界区代码
# 创建多个线程
threads = []
for i in range(5):
thread = threading.Thread(target=process_function)
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()PV操作是实现进程间同步的重要手段,通过信号量和P/V操作可以有效地解决临界区问题、生产者-消费者问题等多种同步问题。在现代操作系统中,PV操作被广泛应用于多线程编程和并发控制中。
1、某企业生产流水线M 共有两位生产者,生产者甲不断地将其工序上加工的半成品放入半成品箱,生产者乙从半成品箱取出继续加工。假设半成品箱可存放n 件半成品,采用PV 操作实现生产者甲和生产者乙的同步可以设置三个信号量S、S1 和S2,其同步模型如下图所示

信号量S 是一个互斥信号量,初始值为(22);S1、S2 的初始值分别为(23)
这里成品箱看作控制信号量(互斥信息号量)其初始值为1 ,s1,s2的初值分别为n 和0 。
2、假设系统中有n个进程共享3台打印机,任一进程在任一时刻最多只能使用1台打印机。若用PV操作控制n个进程使用打印机,则相应信号量S的取值范围为____(1)____;若信号量S的值为-3,则系统中有____(2)____个进程等待使用打印机。
在使用PV(也称为P和V,或者wait和signal)操作来同步进程对共享资源(如打印机)的访问时,信号量是一个非常重要的工具。信号量可以用来确保多个进程不会同时访问同一资源,从而避免冲突。
我们有3台打印机,所以信号量 S 的最大值应该是3,表示所有打印机都可用。当一个进程开始使用打印机时,它会执行P(S)操作,这将使信号量的值减1。当进程完成并释放打印机时,它会执行V(S)操作,这将使信号量的值加1。
因此,信号量 S 的取值范围取决于以下几个因素:
如果没有任何进程在等待,也没有任何打印机被占用,那么S = 3。如果有1台打印机被占用,那么S = 2;如果有2台打印机被占用,那么S = 1;如果有3台打印机都被占用但没有进程等待,那么S = 0。如果已经有进程开始等待,那么S 的值就会小于0,每多一个等待的进程,S 的值就减少1。
所以信号量S 的取值范围为3,2,1,0,-1,…-(n-3)
如果信号量 S 的值是 -3,这意味着所有的3台打印机都被占用了,并且除了已经占用打印机的进程外,还有3个额外的进程正在等待使用打印机。因此,此时有3个进程正在等待。
多级存储:一般cpu 寄存器、由高速缓存、内存、外存三级构成。
内存编址:RAM 存取方式需对每个存储单元进行编址、通常使用字节编址、也就是一个内存单元存放字节的大小,例如地址从A4000H~CBFFFH 则表示(CBFFFH-A4000H)+1个字节,即28000H字节。如果芯片的容量是4K*4b,那么一共需要个芯片。
首先,将16进制数 28000H 转换为十进制数。根据16进制到十进制的转换规则:
2 × 16^48 × 16^30 × 16^20 × 16^10 × 16^0因此,28000H 转换成十进制数为:
2×164+8×163+0×162+0×161+0×1602×164+8×163+0×162+0×161+0×160
=2×65536+8×4096+0+0+0=2×65536+8×4096+0+0+0
=131072+32768=131072+32768
=163840=163840
这意味着 28000H 表示的字节数为 163840 字节。
1 KB (kilobyte) 等于 1024 字节。因此,要将字节数转换为KB,我们需要将字节数除以 1024。
163840÷1024=160163840÷1024=160
因此,28000H 表示的字节数转换为KB为 160 KB。
28000H 表示的字节数为 163840 字节。160KB/(4K*4b)=160K*8b/(4K*4b)=80(片)
地址编号从80000H 到BFFFFH且按字节地址的内存容量是(256)KB,若用16K*4bit 的存储芯片构成该内存,共需(32)片。
BFFFF-8000H+1 =40000H
40000H 转换成十进制为4*16的4次方等于256KB 、256KB/(16KB*4bit)=32
好的,让我们将16进制数 40000H 表示的字节数转换为千字节(KB)。
首先,将16进制数 40000H 转换为十进制数。根据16进制到十进制的转换规则:
4 × 16^40 × 16^30 × 16^20 × 16^10 × 16^0因此,40000H 转换成十进制数为:
4×164+0×163+0×162+0×161+0×1604×164+0×163+0×162+0×161+0×160
=4×65536+0+0+0+0=4×65536+0+0+0+0
=262144=262144
这意味着 40000H 表示的字节数为 262144 字节。
1 KB (kilobyte) 等于 1024 字节。因此,要将字节数转换为KB,我们需要将字节数除以 1024。
262144÷1024=256262144÷1024=256
因此,40000H 表示的字节数转换为KB为 256 KB。
40000H 表示的字节数为 262144 字节。假定磁盘有 200 个柱面,编号 0~199 , 如果在访问 143 号柱面的请求者服务后,当前正在访问125 号柱面的服务请求, 如果请求队列的先后顺序是: 86 , 147 , 91 , 177 , 94 , 150 , 102 , 175 , 130 ; 试问: 为完成上述请求, 下列算法存取臂移动的总量是多少?并算出存取臂移动的顺序。
先来先服务:的算法访问柱面的移动顺序为: 86 , 147 , 91 , 177 , 94 , 150 , 102 , 175 , 130
最短寻道优先算法:移动顺序为:130、147、150、175、177、102、94、91、86
扫描算法(电梯调度算法):这里要注意磁盘运行的方向从143-125可以理解为电梯向下、在向下的过程中最近的为102、94、91、86、130、147、150、175、177。
循环扫描算法:是对扫描算法的改进、143-125(自里向外结束后又从最里面向外)那么顺序为:130、147、150、175、177(这里最外层结束后又从最内开始)、86、91、94、102
在磁盘调度管理中,应先进行移臂调度,再进行旋转调度(也就是扇区由小到大访问)。假设磁盘移动臂位于21号柱面上,进程的请求序列如下表所示。如果采用最短移臂调度算法,那么系统的响应序列应为( )。
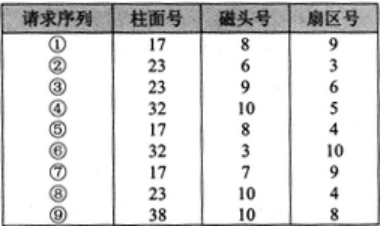
首先按照寻道最短优先进行访问柱面号的顺序号为:21-23-17-32-38 ,23柱面按扇区从小到在访问为(2、8、3)17柱面按扇区访问顺序为(5、7、1或者5、1、7);32柱面访问顺序为(4、6)38柱面为顺序为9 因此响应序列为2、8、3、5、7、1、4、6、9
在磁盘上存储数据的排列方式会影响服务的总时间。假设每个磁道被划分成10个物理 块,每个物理块存放1个逻辑记录。逻辑记录R1,R2,…,R10存放在同一个磁道上,记录的排列顺序如下表所示

假定磁盘的旋转速度为10ms/周,磁头当前在R1的开始处。若系统顺序处理这些记录, 使用单缓冲区,每个记录处理时间为2ms,则处理这10个记录的最长时间为 (27) ;若对存储数据的排列顺序进行优化,处理10个记录的最少时间为 (28) 。(2021年下半年第27、28题)
1、R1:处理时间为:10ms/周 也就是一个10物理块每个使用了1ms 加个处理时间为2ms = 3ms 、处理完R1此时磁头位置R4、再处理R2需要经过8个物理块(R4->R2 4、5、6、7、8、9、10、1)每个需要1秒也就是要8秒;加上处理完R2需要时间3秒等于11秒。也就是除R1外其它物理块每个需要11(3+8)秒,合计需要3+11*9=102秒。
2、如果对数据排列进行优化,每个处理3秒、合计为3*10=30秒,也就是R4存放R2依此类推。
在磁盘上存储数据的排列顺序会影响 I/O 服务的总时间。假设每道划分成 10 个物理块,每块存放 1 个逻辑记录。逻辑记录 R1、R2、…、R10 存放在同一个磁盘上,记录的安排顺序如下表示:

假定磁盘的旋转速度为 30ms/周,磁头当前处在 R1 的开始处。若系统顺序处理这些记录,使用单缓冲区,每个记录处理时间为 6ms,则处理这 10 个记录的最长时间为(4);若对信息存储进行优化后,处理 10 个记录的最少时间为(5)。

假设某计算机的字长为32位,该计算机文件管理系统磁盘空间管理采用位示图,记录磁盘的使用情况,若磁盘的容量为300GB,物理块的大小为4MB,那么位示图的大小为(2)个字节。(2020年)
(2)A.2400 B.3200 C.6400 D.9600
答案:A
解析:字长为32位,表示1个字记录32位物理块
已知磁盘容量为300GB,物理块大小为4MB
则计算物理块数=300*1024/4=76800(个)
位示图大小=76800/32=2400
位视图是用来表示磁盘块使用状况的概念,一个字表示32个物理块的使用的使用状况、计算位视图的大小,需要将物理块的大小除以32,得到的结果即为位视图的大小。
首先,我们需要计算磁盘的物理块总数。磁盘的容量为300GB,物理块的大小为4MB。
将磁盘容量转换为MB,以便与物理块大小单位一致:
300GB=300×1024MB=307200MB
磁盘的物理块总数为:
物理块总数=磁盘容量物理块大小=307200MB/4MB=76800

这意味着磁盘共有76800个物理块。
位示图中的每一个位代表一个物理块的状态(使用或未使用)。因此,位示图需要的位数等于磁盘的物理块总数。
位示图位数=物理块总数=76800位示图位数=物理块总数=76800
字长为32位,表示1个字记录32位物理块 76800/32=2400
cpu主频=外频*倍频
串联和并联系统可靠性
串联可靠性:R=r1*r2*r3(有个的部件工作异常,整个系统瘫痪)
并联可靠性:R=1-(1-r1)*(1-r2)*(1-r3)(有冗余的作用,例如有多个内存条,多个CPU)
总结:系统中有N个并发进程、若规定每个进程需要申请R个某类资源、则当系统提供K=n*(R-1)+1个同类资源时、无论采用何种方式申请使用,一定不会发生死锁。
https://www.cnblogs.com/wkfvawl/p/11598647.html
进程P有8个页面,页号分别为0-7,页面大小为4K,假设系统给进程P分配了4个存储块P,进程P的页面变换表如下所示。表中状态位等于1和0分别表示页面在内存和不在内存。若进程P要访问的逻辑地址为十六进制5148H,则该地址经过变换后,其物理地址应为十六进制( );如果进程P要访问的页面6不在内存,那么应该淘汰页号为( )的页面。

盘存取时间由三个主要部分组成:寻道时间、旋转延迟时间和数据传输时间。如果磁盘的转速提高一倍,会对其中的旋转延迟时间和数据传输时间产生影响,但对寻道时间没有直接影响。下面我们详细分析这三部分:
1. 寻道时间(Seek Time)
定义:寻道时间是指磁头移动到目标磁道所需的时间。
影响:寻道时间主要取决于磁头的机械运动速度,与磁盘的转速无关。因此,即使磁盘的转速提高一倍,寻道时间也不会发生变化。
2. 旋转延迟时间(Rotational Latency)
定义:旋转延迟时间是指磁盘旋转到目标扇区位于磁头下方所需的时间。
影响:旋转延迟时间与磁盘的转速直接相关。磁盘的转速提高一倍,意味着磁盘的旋转周期减半。因此,旋转延迟时间也会减半。

3. 数据传输时间(Transfer Time)
定义:数据传输时间是指从磁盘读取或写入数据所需的时间。
影响:数据传输时间与磁盘的转速和数据传输速率有关。转速提高一倍,意味着数据传输速率也会提高一倍,因此数据传输时间会减半。

总结
寻道时间:不变
旋转延迟时间:减半
数据传输时间:减半
因此,如果磁盘的转速提高一倍,总的磁盘存取时间将会显著减少,主要是因为旋转延迟时间和数据传输时间都减半了。寻道时间虽然没有变化,但整体存取时间的减少仍然会带来性能的提升。
计算机中机械硬盘的性能指标包括磁盘转速及容量、平均寻道时间。
硬盘平均访问时间=平均寻道时间+平均等待时间。
1)平均寻道时间:硬盘磁头从一个磁道移动到另一个磁道所需要的平均时间。它描述硬盘读取数据的能力,单位为毫秒。
2)平均等待时间:数据所在的扇区转到磁头下方的平均时间。一般认定,平均等待时间=1/2×磁盘旋转一周的时间。
SSD性能指标,如IOPS、带宽、延迟、顺序读写和随机读写性能
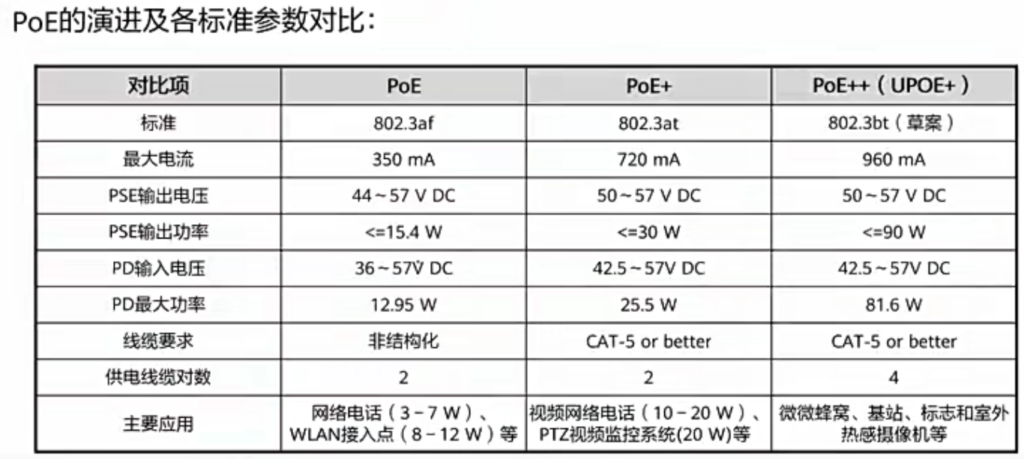
POTS 接口也就是传统电话业务接口 使用RJ11 小型ONU 一般是RJ11
MxU设备使用D型POTS口,常见有68PIN公头
