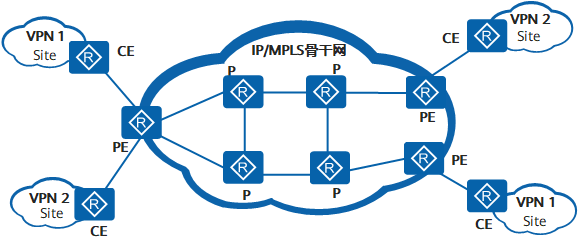
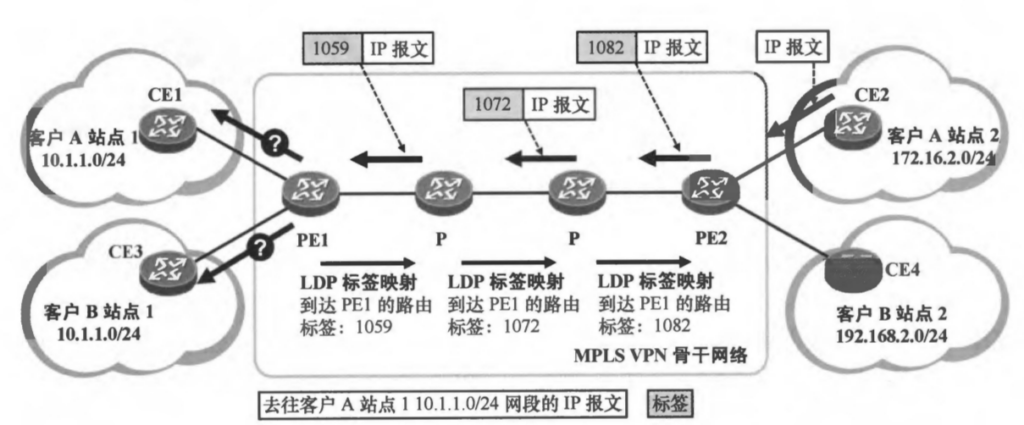
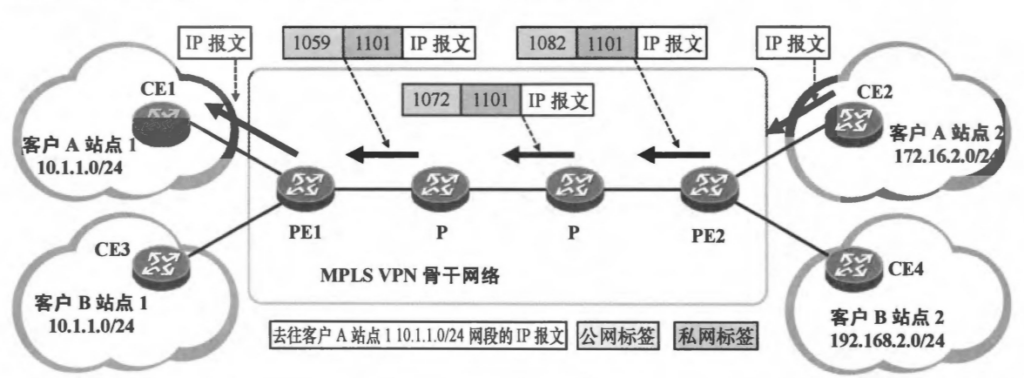
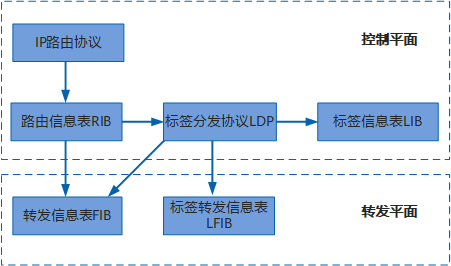
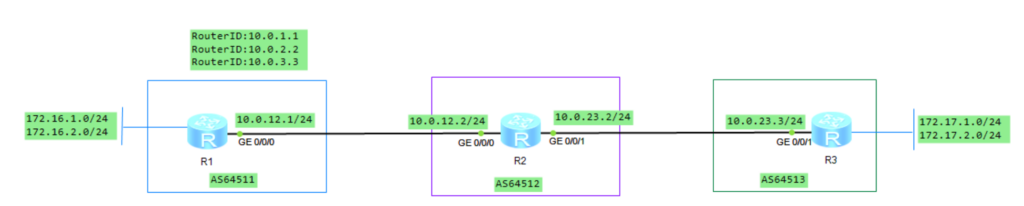
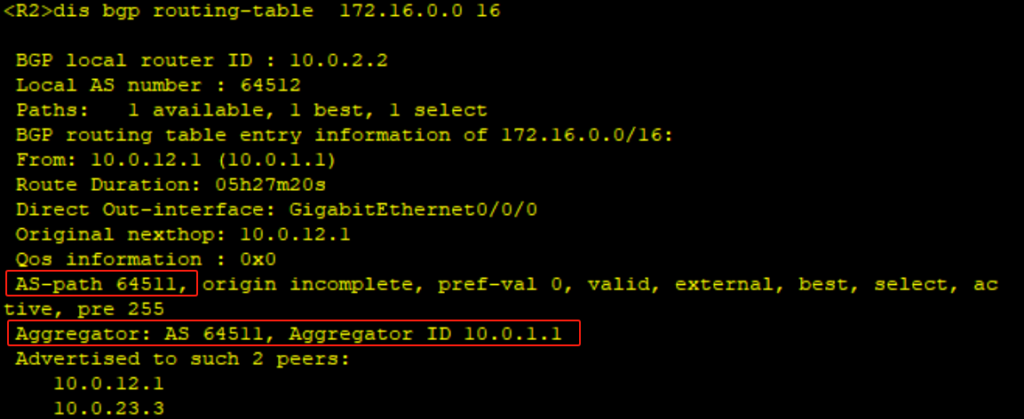
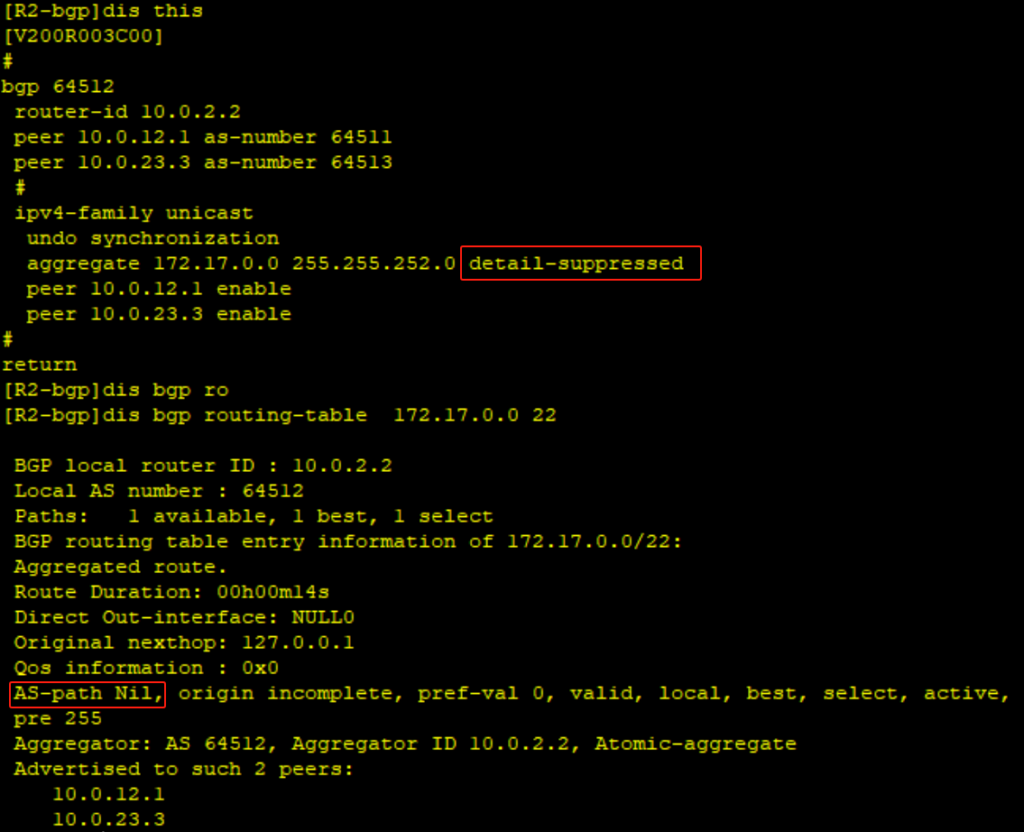
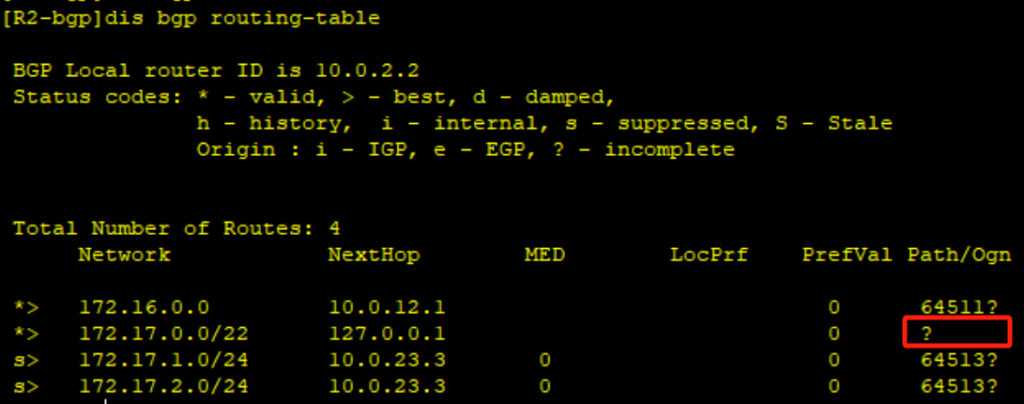
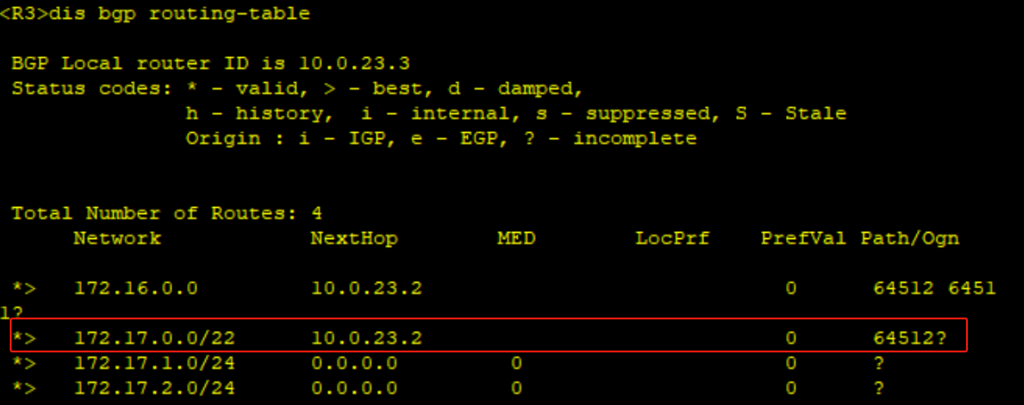
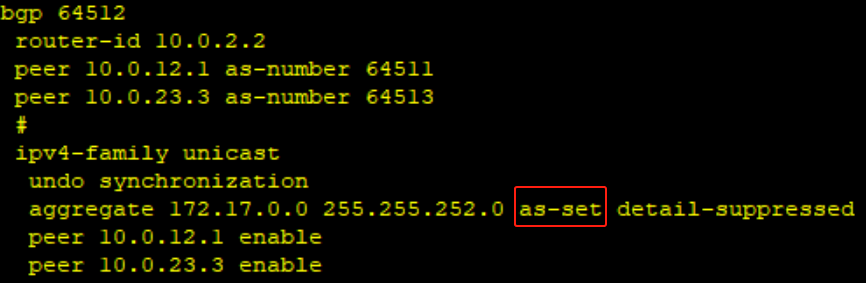
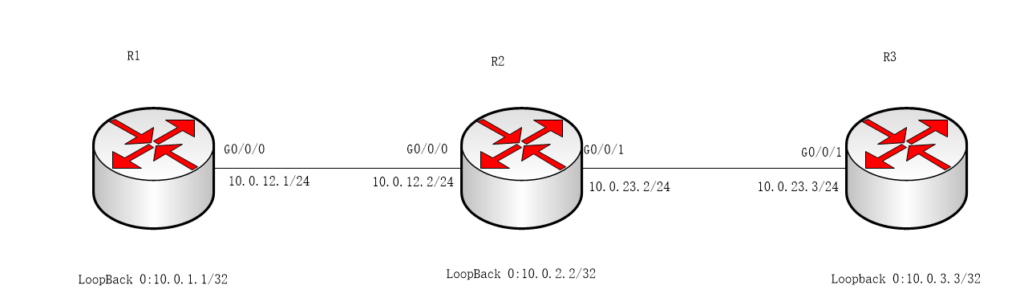
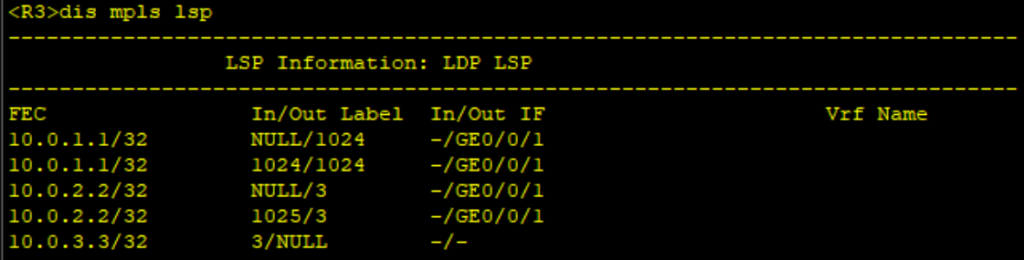
实验拓扑
实验目标
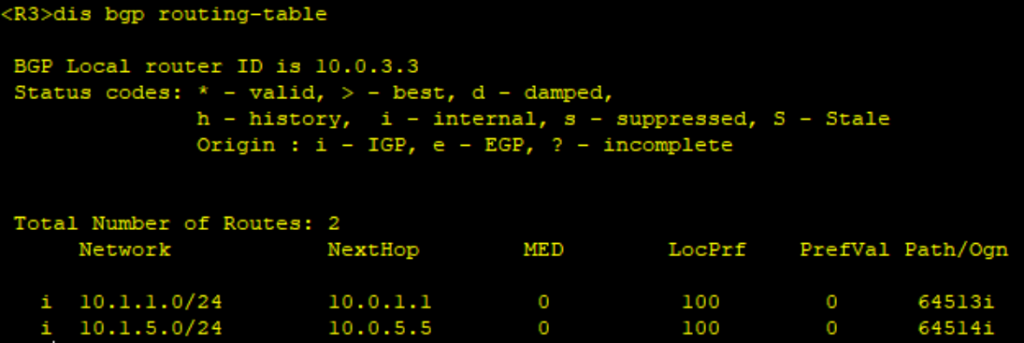
1、实现CE1 和 CE2 通过部署BGP MPLS IP VPN 联通。
配置步骤
- P、PE之间配置OSPF,实现骨干网的IP连通性。
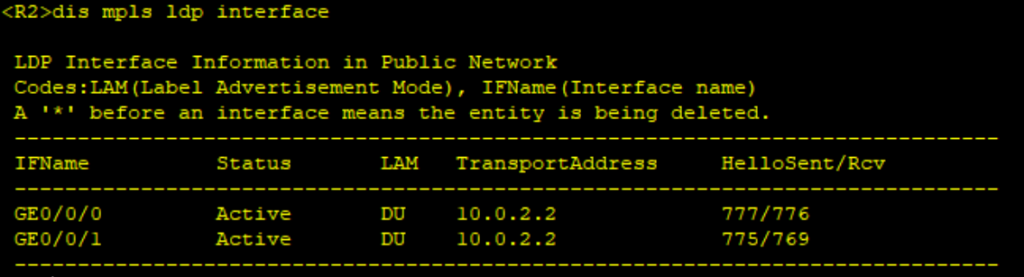
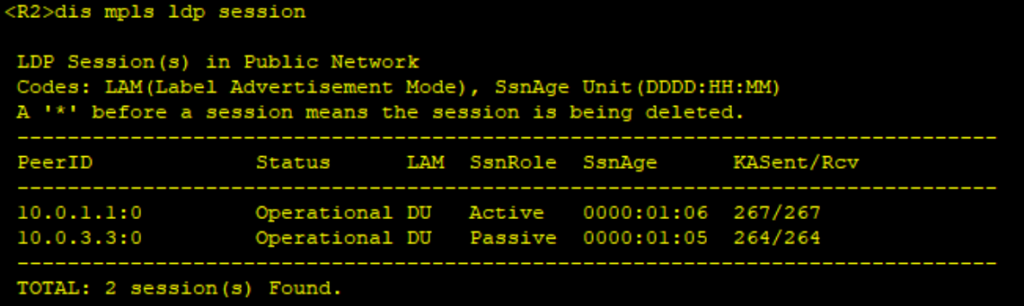
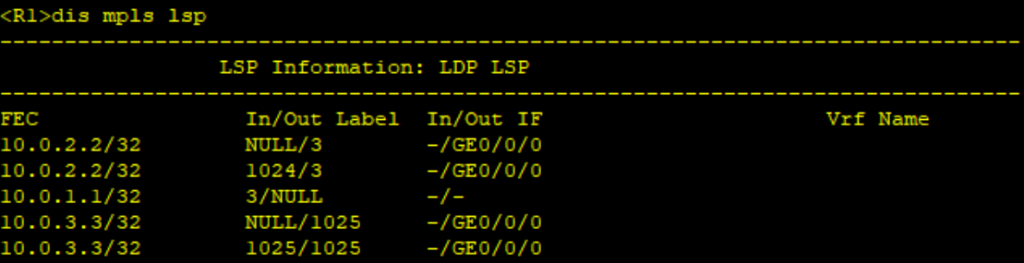
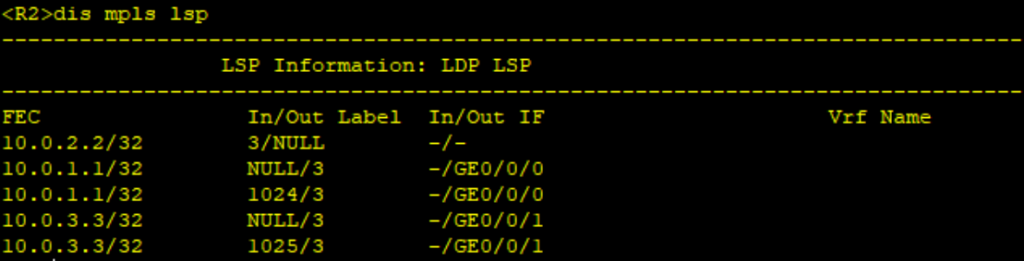
- PE、P上配置MPLS基本能力和MPLS LDP,建立MPLS LSP公网隧道,传输VPN数据。
- PE1和PE2上配置VPN实例,其中PE1,vpnA使用的VPN-target属性为export 64538:1,import 64539:2 以实现相同VPN间互通,同时,与CE相连的接口和相应的VPN实例绑定,以接入VPN用户。
- PE1和PE2之间配置MP-IBGP,交换VPN路由信息。
- CE1与PE1之间配置EBGP,交换VPN路由信息。CE2与PE2 配置ospf 交换VPN 路由信息。
PE1关键配置
接口配置
dis current-configuration interface
[V200R003C00]
#
interface GigabitEthernet0/0/0
ip binding vpn-instance A // 将vpn 实例绑定到接口
ip address 172.16.0.1 255.255.255.252
#
interface GigabitEthernet0/0/1
ip address 10.0.23.2 255.255.255.0
mpls
mpls ldp
#
interface GigabitEthernet0/0/2
#
interface NULL0
#
interface LoopBack0
ip address 2.2.2.2 255.255.255.255
#
return
在接口视图下,使ip binding vpn-instance 命令,可以将该接口分配给指定的 VRF 。在以上配置中,设备的 GEO/O/0 接口被分配给了 VRF customer 。需注意的是,如果接口原来已经存在 IP地址等配置,则将其分配给 VRF 后,这些配置将会被清空,此时需重新为接口配置 IP地址。
VRF 的配置
vpn-target export-extcommunity 和 vpn-target import-extcommunity 命令则分别用于配置该 VRF Export与RT ImportRT 值。
dis current-configuration configuration vpn-instance
[V200R003C00]
#
ip vpn-instance A
ipv4-family
route-distinguisher 64538:100
vpn-target 64538:1 export-extcommunity
vpn-target 64539:2 import-extcommunity
#
return
华为数通产品上 、VRF 的名称是大小写敏感的,因此 VRFA VRFa 是两个不同的 VRF。另外,一旦 VRF 指定了 RD 值,那么该 VRF RD 将不能再被修改,如需在 VRF 中修改 RD ,则需先在系统视图下执行 undo ip vpn-instance 命令将指定的 VRF删除,然后重新创建 VRF 并为其指定新的 RD
路由配置( PE1-CE1)通过BGP 交互路由
PE1
dis current-configuration configuration bgp
[V200R003C00]
#
bgp 2345
router-id 2.2.2.2
undo default ipv4-unicast
peer 5.5.5.5 as-number 2345
peer 5.5.5.5 connect-interface LoopBack0
#
ipv4-family unicast
undo synchronization
undo peer 5.5.5.5 enable
#
ipv4-family vpnv4
policy vpn-target
peer 5.5.5.5 enable
#
ipv4-family vpn-instance A // PE 和CE 通过Ebgp交互VPNv4路由。
router-id 172.16.0.1
peer 172.16.0.2 as-number 64538
#
return
路由配置
如果客户站点的网络规模较小,在 PE-CE 之间部署静态路由的确可行,但是一旦客户站点网络规模变大,静态路由的可扩展性就将受到挑战,网络管理员的工作量也将相应增加:再者,当站点网络发生变更时(例如增加或删除网段), PE 设备是无法动态感知的,因此在多数场景下,在 PE-CE 间部署动态路由协议要显得更加实际。
在CE1 上配置BGP
dis current-configuration configuration bgp
[V200R003C00]
#
bgp 64538
router-id 172.16.0.2
peer 172.16.0.1 as-number 2345
#
ipv4-family unicast
undo synchronization
network 172.16.1.0 255.255.255.0 // 发布路由
peer 172.16.0.1 enable
#
return
CE2和PE2 通过 ospf 交互路由
查看PE2的VRF
dis current-configuration configuration vpn-instance
[V200R003C00]
#
ip vpn-instance A
ipv4-family
route-distinguisher 64539:200
vpn-target 64539:2 export-extcommunity
vpn-target 64538:1 import-extcommunity
#
return
查看PE2 OSPF 配置
PE2>dis current-configuration configuration ospf
[V200R003C00]
#
ospf 1 vpn-instance A // 创建了ospf 为1 的进程绑定了vpn-instance A
import-route bgp
area 0.0.0.0
network 172.16.0.4 0.0.0.3
#
ospf 100 router-id 5.5.5.5
area 0.0.0.0
network 5.5.5.5 0.0.0.0
network 10.0.45.0 0.0.0.255
在华为路由器上可以创建多个 OSPF 进程,每个 OSPF 进程使用Process-ID 进行标识。同 台网络设备上的不同 OSPF 进程之间相互独立,互不影响。设备会分别为这些 OSPF 进程维护不同的 LSDB ,从一个进程学习到的 LSA 仅仅存储在该进程的 LSDB 中。
如果没有在 ospf 命令中使用 vpn-instance 关键字,那么被创建的 OSPF 进程是部署在设备的根实例中的,设备通过该进程所获悉的 OSPF 路由会被加载到其全局路由表中。
ospf 命令中指定了vpnn-instance 关键字,这意味着该命令所创建的 OSPF 进程被绑定到了某个 VRF ,而不再属于根实例。
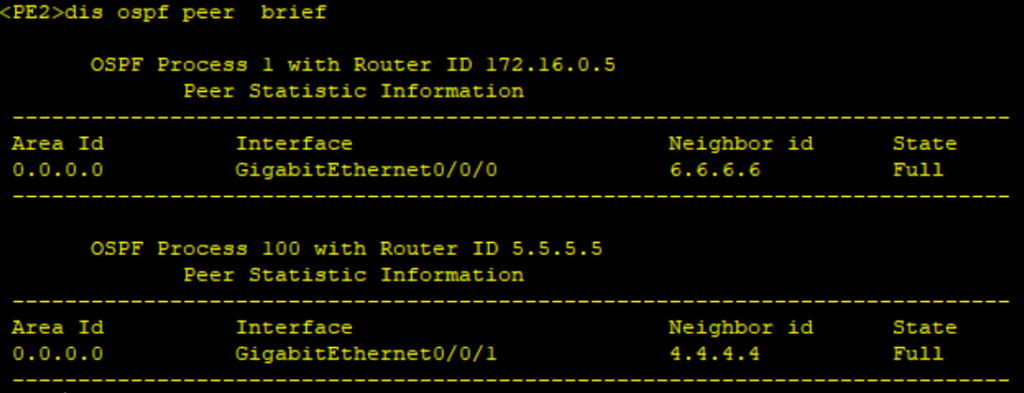
查看PE2 OSPF 对等体
dis ospf peer
OSPF Process 1 with Router ID 172.16.0.5
Neighbors Area 0.0.0.0 interface 172.16.0.5(GigabitEthernet0/0/0)’s neighbors
Router ID: 6.6.6.6 Address: 172.16.0.6
State: Full Mode:Nbr is Slave Priority: 1
DR: 172.16.0.5 BDR: 172.16.0.6 MTU: 0
Dead timer due in 37 sec
Retrans timer interval: 5
Neighbor is up for 00:35:34
Authentication Sequence: [ 0 ]
OSPF Process 100 with Router ID 5.5.5.5
Neighbors Area 0.0.0.0 interface 10.0.45.5(GigabitEthernet0/0/1)’s neighbors
Router ID: 4.4.4.4 Address: 10.0.45.4
State: Full Mode:Nbr is Slave Priority: 1
DR: 10.0.45.5 BDR: 10.0.45.4 MTU: 0
Dead timer due in 36 sec
Retrans timer interval: 5
Neighbor is up for 00:35:33
Authentication Sequence: [ 0 ]
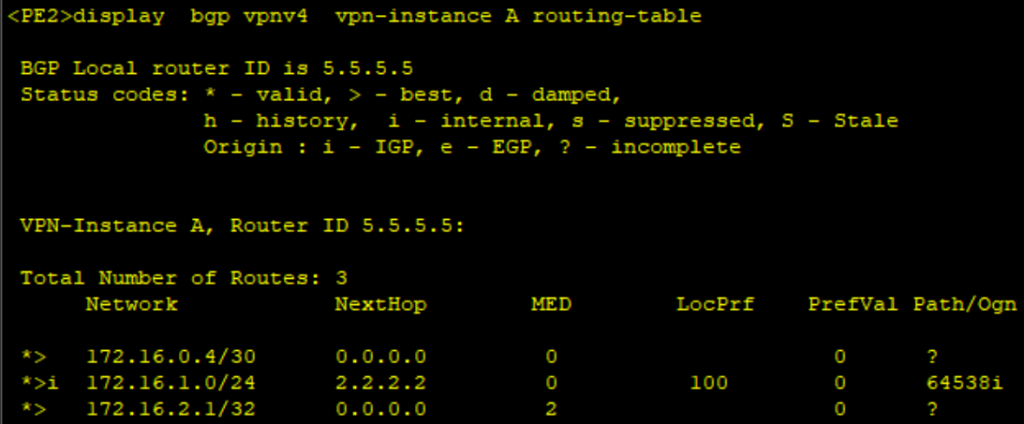
查看路由实例表
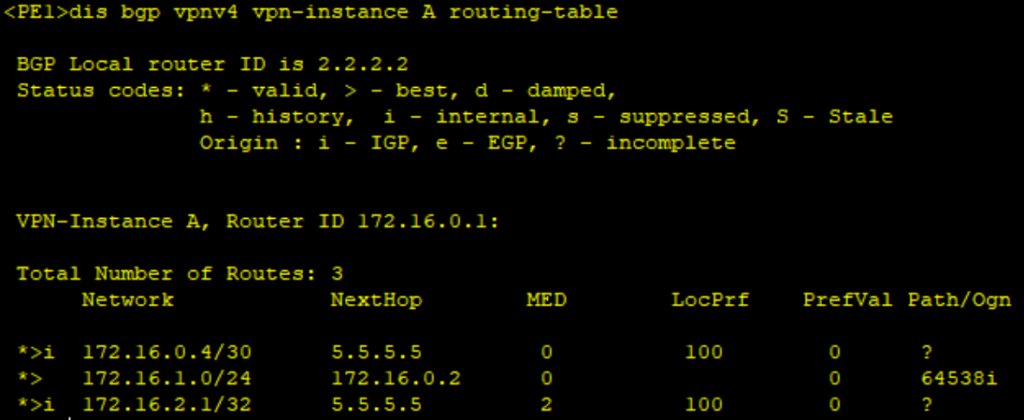
dis ip routing-table vpn-instance A
在PE2上导入从OSPF 学习的客户路由
dis current-configuration configuration bgp
[V200R003C00]
#
bgp 2345
router-id 5.5.5.5
undo default ipv4-unicast
peer 2.2.2.2 as-number 2345
peer 2.2.2.2 connect-interface LoopBack0
#
ipv4-family unicast
undo synchronization
peer 2.2.2.2 enable
#
ipv4-family vpnv4
policy vpn-target
peer 2.2.2.2 enable
#
ipv4-family vpn-instance A //在BGP 视图中执行ipv4-family vpn-instance A 进入地址族视图
import-route ospf 1
#
return
为了达到上述目的,直接在 BGP 配置视图下执行 import-route 命令是不行的,因为这个操作只会将 PE2 的全局路由表中的 OSPF 由引入 BGP ,这显然与需求不符。要将 PEl2学习到的客户 CE2的路由引入 MP-BGP ,就必须在 BGP 配置视图 中,先执行 ipv4-family vpn-instance A 命令进入相应的地址族视图,然后再执行import-route ospf 命令将 PE2 VRF 路由表中通过 OSPF 进程 学习到的OSPF 路由引 BGP 。
在PE1-CE1 之间部署BGP与PE2-CE2 之间部署OSPF路由引入的差异
由于 PE 设备采用不同的 VRF 对接不同的客户,因此 PE 备与客户的 CE 设备建立
BGP 对等体关系时,必须在 VRF IPv 4地址族中指定对等体。另外,与使用 OSPF
等动态路由协议交互路由的场景不同,当 PE-CE 之间使用 BGP 交互客户路由时,无需
手工执行路由引入操作。 PE 设备通过 BGP 从其直连 CE 设备所学习到的 BGP 路由,可
直接转换成 VPNv4 路由,然后通告给远端 PE 设备: 而其从远端 PE 设备学习到的 VPNv4
路由,也无需手工执行引入操作,可 接转换成 IPv4 路由,然后通过 PE-CE 间的 BGP对等体关系,通行给相应的PE 设备。
PE1 BGP 配置
dis current-configuration configuration bgp
[V200R003C00]
#
bgp 2345
router-id 2.2.2.2
undo default ipv4-unicast
peer 5.5.5.5 as-number 2345
peer 5.5.5.5 connect-interface LoopBack0
#
ipv4-family unicast
undo synchronization
undo peer 5.5.5.5 enable
#
ipv4-family vpnv4
policy vpn-target
peer 5.5.5.5 enable
#
ipv4-family vpn-instance A
router-id 172.16.0.1
peer 172.16.0.2 as-number 64538
#
return
在上述配置中, PEl 指定了对等体 5.5.5 .5 (PE2) 及其所处的 AS 号,并且在 VPNv4 单播
地址族中激活了该对等体。由于 PEl PE2 之间仅需交互 VPNv4 路由,尤需交互IPv 4路由,
因此使用 undo default ipv4-unicast 命令配置 BGP 缺省不在IPv 4单播胁地址族中激活对等体。
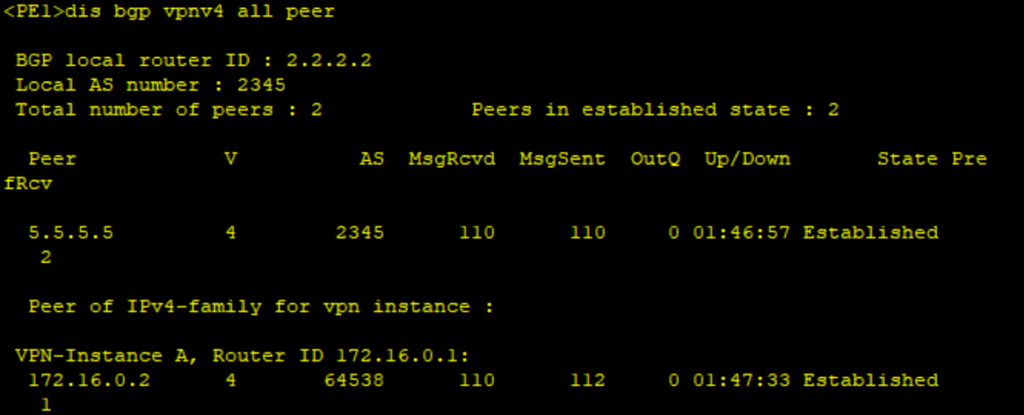
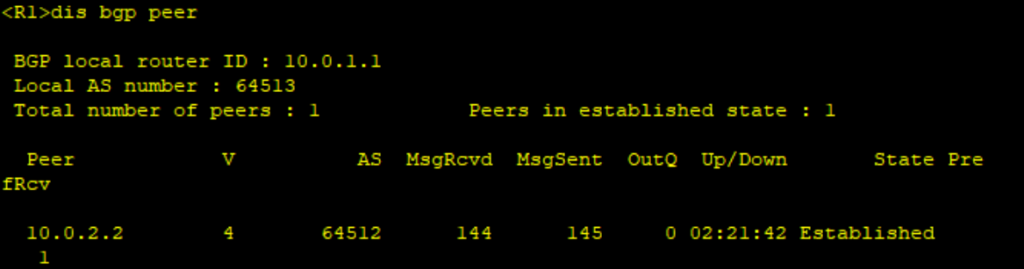
查看PE1 VPNv4的对等体