单点路由重分发是指的是在2个路由域之间的一台边界设备上执行路由重分发的场景,这种场景相对简单,缺乏冗余性,一旦边界设备上发生故障,那么譔设备所连接的2个路由域通信就中断了。
双向重分发的场景中存在两台边界设备,而且这两台设备都执行了路由重分发的操作。
双点双向路由重分发虽然增强了网络的可靠性,但是在双点(两台边界设备)上执行双向路由重分发后,次优路径、路由环路及路由倒灌等问题是非常容易被引发的。
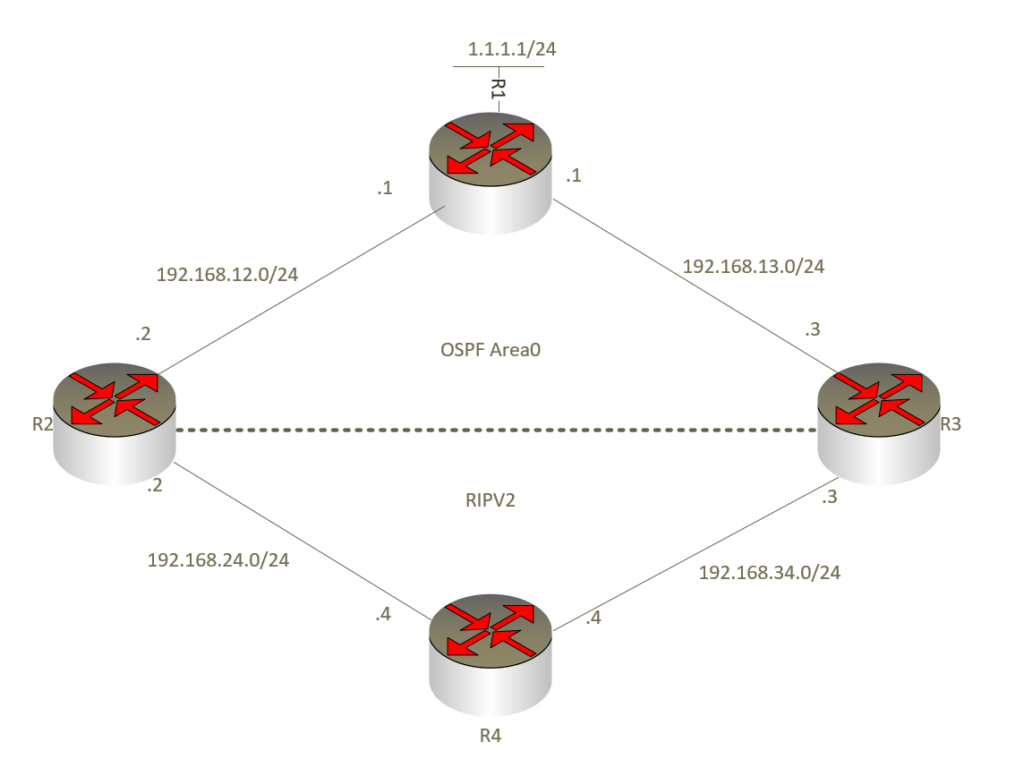
配置完常规的路由重分发,观察R4去往1.1.1.1的路由,下一跳只出现了R2/R3其中的一台 ?
到达 OSPF 域的路由 192 168.12.0/24 192.168.13.0/24 的确是出现了等价负载分担,这属于正常。
从以上输出可以看出 R3 的路由表中1.1.1.0/24 路由竟然来源于RIP ,这显然是有问题的,因为这条路由是在 OSPF 中发布的, R3 达该目标网段,理应优选 OSPF 路由,下一跳应该是 Rl 才合理。
然而此时 R3 的路由表中该条路由却是来源于R1 ,而且下一跳为 R4 ,这就出现了次优路径现象一R3 转发到达1.1.1.0/24 的数据时,使用的转发路径为 R4-R2-Rl 。为什么会出现这样的现象?为什么只有1.1.1. 0/24 这条 OSPF 外部路由才会出现这样的现象?
在华为的数通产品上, R1 由的优先级值是 100 OSPF 路由有两个优先级,其中内部路由的优先级值为 10 ,外部路由则为 150 。
双点双向路由重分发是一个经典的课题,这种类型的网络很容易出现路由环路或者
次优路径问题。解决的方法也是多种多样的,解决方案的核心思想是在R2及R3上,将1.1.1.0/24 这条 OSPF 外部路由的优先级值调节得比RIP路由的优先级值更小(例如调整为 99)
R1 dis current-configuration
[V200R003C00]
#
sysname R1
acl number 2000
rule 5 permit source 1.1.1.0 0
#
interface GigabitEthernet0/0/0
ip address 192.168.12.1 255.255.255.0
#
interface GigabitEthernet0/0/1
ip address 192.168.13.1 255.255.255.0
interface LoopBack0
ip address 1.1.1.1 255.255.255.0
#
ospf 1 router-id 1.1.1.1
import-route direct route-policy hcnp
area 0.0.0.0
network 192.168.12.0 0.0.0.255
network 192.168.13.0 0.0.0.255
#
route-policy hcnp permit node 10
if-match acl 2000
R2 配置
sysname R2
acl number 2000
rule 5 permit source 1.1.1.0 0
interface GigabitEthernet0/0/0
ip address 192.168.12.2 255.255.255.0
#
interface GigabitEthernet0/0/1
ip address 192.168.24.2 255.255.255.0
#
interface GigabitEthernet0/0/2
#
ospf 1 router-id 2.2.2.2
import-route rip 1
preference ase route-policy hcnp 150
area 0.0.0.0
network 192.168.12.0 0.0.0.255
#
rip 1
undo summary
version 2
network 192.168.24.0
import-route ospf 1
#
route-policy hcnp permit node 10
if-match acl 2000
apply preference 99
#
R3 的配置
sysname R3
#
acl number 2000
rule 5 permit source 1.1.1.0 0
#
#
interface GigabitEthernet0/0/0
ip address 192.168.13.3 255.255.255.0
#
interface GigabitEthernet0/0/1
ip address 192.168.34.3 255.255.255.0
#
#
ospf 1 router-id 3.3.3.3
import-route rip 1
preference ase route-policy hcnp 150
area 0.0.0.0
network 192.168.13.0 0.0.0.255
#
rip 1
version 2
network 192.168.34.0
import-route ospf 1
#
route-policy hcnp permit node 10
if-match acl 2000
apply preference 99
#
R4 的配置
sysname R4
#
interface GigabitEthernet0/0/0
ip address 192.168.24.4 255.255.255.0
#
interface GigabitEthernet0/0/1
ip address 192.168.34.4 255.255.255.0
rip 1
undo summary
version 2
network 192.168.24.0
network 192.168.34.0
#