
浮动静态路由
优先级值高的优先级低,不解决负载均衡,解决了线路冗余。
静态黑洞路由
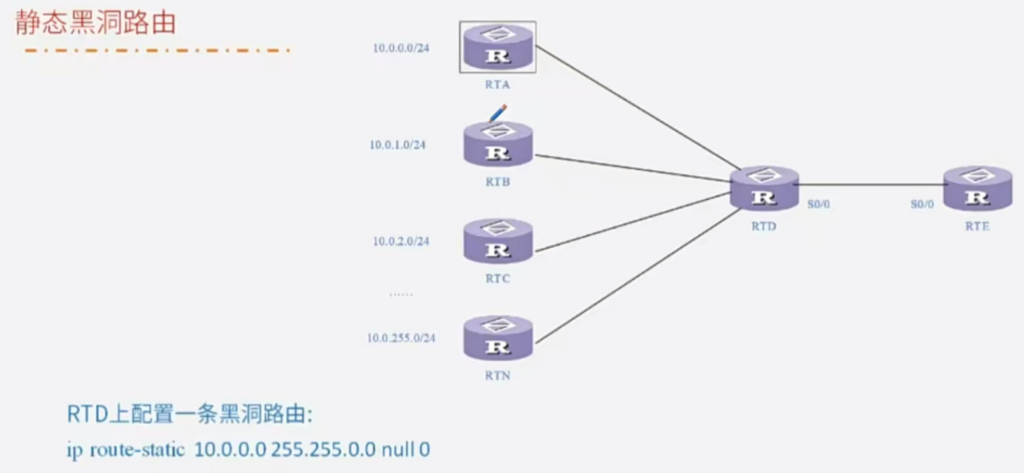
在RTE 上配置路由聚合:ip route-statci 10.0.0.0 255.255.0.0 RTD
在RTC连接RTD线路故障的情况下,如果RTA发往RTC的数据包会在RTD和TRE之间形成环路。加上黑洞路由数据包丢弃。
RIP(Routing Information Protocol,路由信息协议)是一种广泛使用的内部网关协议(IGP),主要用于小型到中型网络中的路由选择。RIP有两种版本:RIPv1 和 RIPv2。RIPv1 是最初的版本,而 RIPv2 支持无类别域间路由(CIDR)和认证功能,是目前更常用的一个版本。
RIP的工作原理概述:
- 度量标准:
- RIP 使用跳数作为度量标准来计算到达目的网络的最佳路径。每个路由器到直接相连的网络的距离定义为1跳。最大跳数为15,超过15跳(即16跳及以上)的目标网络被视为不可达。
- 路由更新:
- RIP 路由器每隔30秒向相邻路由器广播路由更新消息。这些更新包含路由器所知的所有可达网络的列表,以及到达每个网络所需的跳数。
- 路由器接收到更新后,会与自己的路由表进行比较,更新或添加新路由条目。
- 路由选择:
- 路由器选择具有最少跳数的路径作为最佳路径。如果有两条或多条相同跳数的路径,路由器会选择其中一条,通常随机选择或基于其他策略选择。
- 计时器:
- 更新计时器 (Update Timer): 每隔30秒发送一次路由更新。
- 无效计时器 (Invalid Timer): 如果在180秒内没有收到邻居的更新,则认为该邻居不可达,路由变为“无效”状态。
- 清除计时器 (Flush Timer): 在邻居变为“无效”状态后等待240秒,如果在此期间仍未收到更新,则从路由表中删除该路由条目。
- 抑制计时器 (Hold Down Timer): 当一个路由条目的跳数增加时,启动抑制计时器,防止在计时期间内对该路由进行更新,以避免路由抖动。在抑制状态中的路由时收到其它路由器发送的抑制路由时等待的时间
- 水平分割 (Split Horizon):
- 为了避免路由环路,RIP 实施了一种称为水平分割的技术。路由器不会将自己学到的路由信息广播回通告该信息的邻居路由器。
- 毒性反转 (Poison Reverse):
- 为了进一步防止路由环路,当路由器发现一个路由不再有效时,它会在路由更新中将该路由的跳数设置为16(即不可达),并向所有邻居广播这一信息,包括通告该路由的邻居。
- 触发更新 :当路由发现有路由不可达是,立即通报给其它的路由器
- 认证 (Authentication):
- RIPv2 支持明文或MD5密钥认证,以确保路由更新的安全性。
- CIDR 支持:
- RIPv2 支持无类别域间路由(CIDR),允许路由器通告子网掩码和前缀长度,从而支持可变长度子网掩码(VLSM)。
路由协议使用的广播或者组播更新
RIP、OSPF 和 BGP 这三种路由协议在发送路由更新时采用不同的目的 IP 地址和传输机制。下面是每种协议如何发送路由更新的简要说明:
RIP (Routing Information Protocol)
- 目的 IP 地址:
- RIP 使用广播或组播地址来发送更新。
- 对于 RIPv1,默认情况下使用广播地址
255.255.255.255。
- 对于 RIPv2,默认情况下使用组播地址
224.0.0.9。
- 传输层协议:
- RIP 使用 UDP 协议。
- UDP 端口号为
520。
OSPF (Open Shortest Path First)
- 目的 IP 地址:
- OSPF 使用组播地址来发送更新。
- 所有 OSPF 路由器都监听组播地址
224.0.0.5 (所有 DR 路由器)和 224.0.0.6 (所有 SPF 路由器)。
- 传输层协议:
- OSPF 使用 IP 协议直接发送数据包,不使用 UDP 或 TCP。
BGP (Border Gateway Protocol)
- 目的 IP 地址:
- BGP 使用 TCP 连接来发送更新。
- 目的 IP 地址是 BGP 对等体的 IP 地址。
- 传输层协议:
- BGP 使用 TCP 协议。
- TCP 端口号为
179。
总结如下:
| 协议 | 目的 IP 地址 | 传输层协议 | TCP/UDP 端口 |
|---|
| RIP | 255.255.255.255 (RIPv1) 或 224.0.0.9 (RIPv2) | UDP | 520 |
| OSPF | 224.0.0.5 或 224.0.0.6 | IP | N/A |
| BGP | BGP 对等体的 IP 地址 | TCP | 179 |
请注意,RIPv1 使用广播地址,这可能导致广播风暴问题,因此建议使用 RIPv2 的组播地址。另外,OSPF 使用 IP 直接发送数据包,这意味着它不需要使用 UDP 或 TCP 来封装数据包。
负载均衡
多出口负载分担方案是指在网络中通过多个互联网出口来分散流量,以提高网络的可用性、性能和可靠性。这种策略对于大型企业、数据中心以及需要高带宽和高可靠性的机构尤为重要。以下是几种常见的多出口负载分担策略:
- 基于源IP或目的IP的负载均衡:
- 根据数据包的源IP地址或目的IP地址来决定使用哪个出口。这种方法简单直接,但可能导致某些出口过载而其他出口利用率不足。
- 基于会话的负载均衡:
- 对于每个新建的TCP/UDP会话,路由器可以选择一个当前负载较低的出口来转发数据包。这种方式可以较好地平衡各出口之间的流量。
- 基于应用类型的负载均衡:
- 不同类型的应用(如Web浏览、视频流媒体等)对带宽的需求不同,可以根据应用类型选择最合适的出口。例如,将高优先级的应用分配给质量更好的线路。
- 基于带宽利用率的动态负载均衡:
- 监控各个出口的实际带宽使用情况,并根据实时负载动态调整流量分布。当某个出口接近饱和时,新的流量会被导向其他较为空闲的出口。
- 基于地理位置的负载均衡:
- 如果用户群体分布在不同的地理区域,可以根据用户的地理位置选择最近或者最佳路径的出口,减少延迟并优化用户体验。
- 基于链路健康状况的负载均衡:
- 通过持续监测每个出口链路的状态(包括丢包率、延迟等),自动避开故障或性能不佳的链路,确保只有健康的链路参与负载分担。
- 基于权重的负载均衡:
- 给每个出口分配一个权重值,权重值高的出口会被分配更多的流量。这样可以根据链路的质量和服务水平协议(SLA)要求来分配流量。
- 基于策略的负载均衡:
- 结合多种因素制定综合策略,比如结合时间、成本、服务等级等因素来决定如何分配流量。
- ECMP (Equal-Cost Multi-Path) Routing:
- 在路由层面上实现的一种技术,允许路由器在到达同一目的地的多条等价路径上均匀分配流量。这通常用于BGP或多路径OSPF环境中。
实施这些策略通常需要支持高级功能的网络设备,如支持策略路由、负载均衡算法和动态路由协议的路由器或防火墙。同时,也需要考虑网络架构设计、安全性以及与现有网络管理系统的集成。