OSPF网络规划设计原则
保持OSPF网络的稳定性:Router ID的规划
在典型OSPF网络设计和实施中我们需要考虑的第一点,就是Router ID的选择。
这是因为OSPF作为一种链路状态路由协议其计算路由的依据是LSA(链路状态通告),每个运行OSPF的路由器都会发送并泛洪LSA报文到整个网络,这样网络中每个运行OSPF的路由器都会收集到其他设备发送过来的LSA并且放入LSBD(链路状态数据库),然后开始进行SPF(最短路径算法)运算,计算出一棵以自己为根到其他网络的无环树。由此可以看出保持每个路由器LSDB的稳定性是保证OSPF网络稳定的前提。那么在LSDB中对于不同OSPF设备发送来的LSA是如何进行区分的呢,答案就是使用Router ID。如果一个路由器的Router ID发生变化,那么此路由器会重新进行LSA泛洪,从而导致全网OSPF路由器都会更新其LSDB并且重新进行SPF计算,使得OSPF网络发生振荡。因此选择一个稳定的Router ID是OSPF网络设计的首要工作。
了解了Router ID的重要性后,我们来看看一个OSPF路由器是如何选择Router ID的。
路由器的Router ID可以手工配置,如果没有通过命令指定Router ID,系统会从当前接口的IP地址中自动选取一个作为路由器的Router ID。其选择顺序是:优先从Loopback地址中选择最大的IP地址作为路由器的Router ID,如果没有配置Loopback接口,则在接口地址中选取最大的IP地址作为路由器的Router ID。只有当被选举为Router ID的接口IP地址被删除或修改后,才会进行Router ID的重新选举。
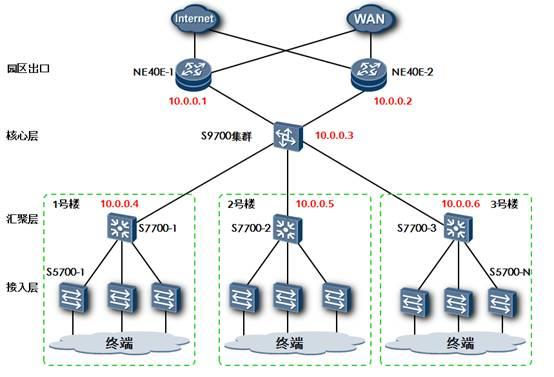
在实际工程中,推荐手工指定OSPF路由设备的Router ID。具体做法是首先规划出一个私有网段用于OSPF的Router ID选择。例如:192.168.1.0/24。在启用OSPF进程前就在每个OSPF路由器上建立一个Loopback接口,使用一个32位掩码的私有地址作为其IP地址,这个32位的私有地址即作为该路由设备的Router ID。如果没有特殊要求,这个Loopback接口地址可以不发布在OSPF网络中。
层次化的网络设计:OSPF区域的规划
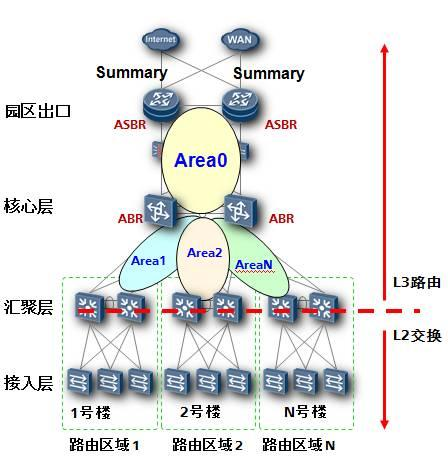
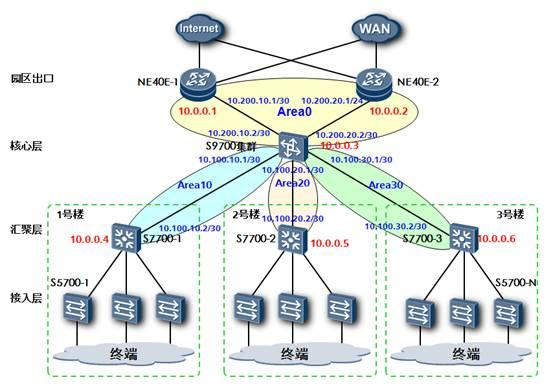
OSPF是一个需要层次化设计的网络协议,在OSPF网络中使用了一个区域的概念,从层次化的角度来看区域被分为两种:骨干区域和非骨干区域。骨干区域的编号为0,非骨干区域的编号从1到4294967295。处于骨干区域和非骨干区域边界的OSPF路由器被称为ABR(区域边界路由器)。
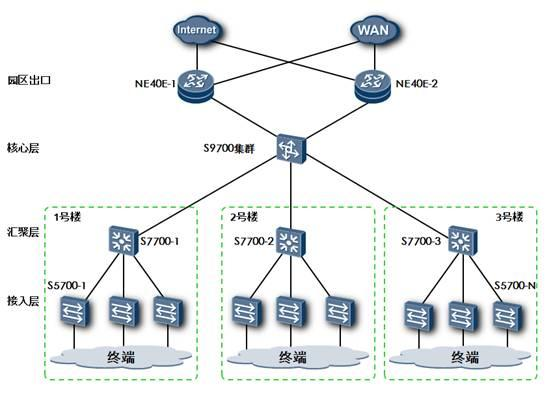
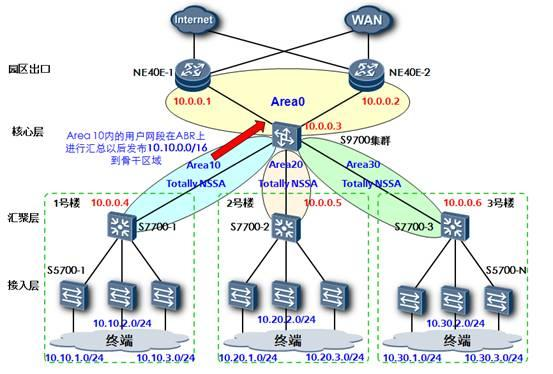
实际上OSPF区域的规划也就是把网络中的OSPF路由器做归类的过程。在设计OSPF区域时,我们首先需要考虑的第一点是网络的规模,对于小型的典型网络,例如只有几台路由设备作为核心和汇聚的网络可以考虑仅规划一个骨干区域Area 0。但是在大型的OSPF网络中,网络的层次化设计是必须要考虑的。
对于大型的OSPF网络,一般在规划上都会遵循核心,汇聚,接入的分层原则,而OSPF骨干路由器的选择必然包含两种设备,一种是位于整网核心位置的核心设备,另一种是位于区域核心的汇聚设备,通常都是高端路由设备,例如华为NE系列高端路由器,或者华为S77&97系列高端路由交换机。非骨干区域的设计则是根据地理位置和设备性能而定,如果在单个非骨干区域中使用了较多的低端三层交换产品,由于其产品定位和性能的限制,应该尽量减少其路由条目数量,把区域规划得更小一些或者使用特殊区域。
实际工程中对于非骨干区域的Area编号的规划也是有讲究的,尽量不要使用类似Area1、2、3……这种连续的编号,推荐使用Area 10 、20 、30……这种递增方式,这样主要是考虑提供Area编号上的冗余,在后期网络扩容的时候便于用户增加区域编号。
非骨干区域的路由表项优化:特殊区域的使用
特殊区域的使用可以达到优化非骨干区域的路由表项的目的。实际上对于非骨干区域,一般可能存在如下两种诉求需要减少路由表项的规模:
1、 非骨干区域仅有一个ABR做出口,任何访问区域外的流量都要经过这个出口设备,此时其实这个区域内的路由器没必要了解外部网络的细节,仅需要有个出口能够出去即可。
2、 有些时候非骨干区域的设备可能使用了一些较为低端的三层交换机,其产品定位使得其不可能承受过多的路由条目,为了精简其路由条目数量可以采用配置特殊区域的方法进行路由表项的优化。
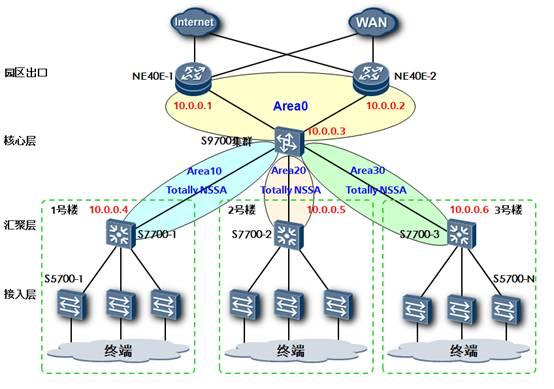
华为路由器和交换机产品支持OSPF协议中定义四种特殊区域类型:Stub区域,Totally Stub区域,NSSA区域,Totally NSSA区域。
在绝大部分的情况下,典型OSPF网络的非骨干区域中都仅仅需要知道缺省路由出口在哪里,因此建议把非骨干区域统一规划成Totally NSSA区域,这样将极大的精简非骨干区域内部路由器的路由条目数量,并且减少区域内部OSPF交互的信息量。对于少数存在特殊需求的网络,请根据实际情况灵活使用几种区域类型。
骨干区域的路由表项优化:非骨干区域IP子网规划和路由汇聚
由于OSPF骨干区域需要负责区域之间的路由交互,所以骨干区域设备的路由表规模往往会比较大,因此骨干区域的路由表规模同样需要考虑精简和优化的问题。
对于OSPF的非骨干区域来说,使用特殊区域能够精简其内部路由器的路由表,那么对于OSPF骨干区域的路由器来说又是如何优化其路由表的呢?答案就是对非骨干区域使用的IP网段作出合理规划以便于区域边界的路由汇聚。
建议新建OSPF网络能够在前期就作出利于路由汇总的IP网络设计,对于扩建的网络尽量进行IP地址的重新规划,通过区域汇总能精简骨干区域路由器的路由表,减少骨干区域内OSPF交互的信息量。同时,路由汇总以后,单点的链路故障或者网络震荡不至于影响整个网络的路由更新,因此路由汇聚还可以提高网络的稳定性。
上行流量的引导:OSPF缺省路由的引入和选路优化
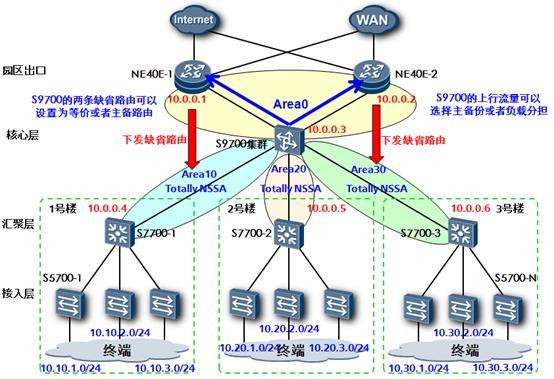
对于一个大型OSPF网络来说,很大一部分的业务流量并不在网络内部,而是通往Internet出口,因此缺省路由的设计也是典型OSPF网络的一大设计要点。
在实际的大多数工程案例中,典型网络的出口往往不止一个,如何有效的将出口流量分担到多条链路上就成为了OSPF设计中的一个难点。虽然有很多种手段能够达到分担流量的目的,但是最简单也是最安全的方法是使用OSPF内在的选路机制。因为OSPF路由器对一条路由的优劣衡量是通过计算其cost值来实现的,cost值小的路由会被路由器优先放入路由表。通过调整OSPF接口的cost值可以使得路由器选择不同的链路出口来达到负载分担的目的。
不过在调整cost值之前还有一项必须要做的工作。因为OSPFv2出现的时间较早,没有考虑到带宽的飞速发展,因此缺省情况下,OSPF计算cost值使用的参考带宽为100M,也就是说缺省情况下,OSPF把100M带宽以上的端口统统认为其cost是1。很明显,在网络骨干带宽迈向10T的今天已经显得非常的不合时宜。幸运的是设备提供了更改参考带宽的功能,使用bandwidth-reference value命令选择一个合适的参考带宽成为OSPF网络建设中必须要做的一项工作。对于OSPF网络的选路优化,推荐首先选择合适的参考带宽,然后通过调整OSPF接口cost值来实现。
路由汇总场景下的防环设计:黑洞路由的使用
而在路由器中黑洞路由类似于宇宙中的黑洞,凡是命中黑洞路由的报文都统统被丢弃,而且不向发送者反馈任何差错信息。
黑洞路由的这种巨大魔力使得它在防止路由环路方面有着广泛的应用。在很多场景下路由聚合确实能够做到精简路由,提高网络稳定性的作用,但是任何事物都具有两面性,路由聚合也不例外,路由聚合带来的缺陷就是容易产生路由环路,而黑洞路由可以用来弥补这种缺陷。所以典型OSPF网络设计中,路由聚合和黑洞路由往往是配合使用的,
OSPF网络基本安全:OSPF静默接口的使用
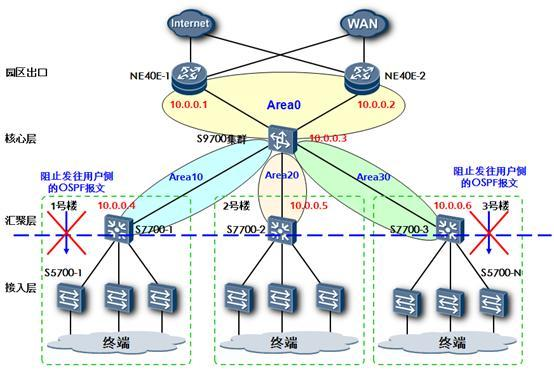
对于一个大型OSPF网络来说,安全性是必须要考虑到的问题。在OSPF网络设计中,通常会禁止将OSPF报文发往用户端,这是为什么呢?这主要是为了防止终端用户窥探OSPF报文信息,因为如果用户能截获OSPF报文,那就意味着他可能知道如何加入此OSPF网络。此时要破坏这个OSPF网络已经是轻而易举的事,例如接入一台路由器到OSPF网络中,并且使得该路由器的OSPF进程处于不稳定的状态中,就会导致OSPF网络发生振荡甚至瘫痪。
在实际工程中,为了保证OSPF网络的安全与稳定,推荐在OSPF网络的边缘设备上使用静默接口的的方式来阻止通往用户侧的OSPF报文。具体做法是在OSPF网络的边缘设备上配置silent-interface命令,用来禁止该接口接收和发送OSPF报文。禁止接口收发OSPF报文后,该接口的直连路由仍可以发布出去,但接口的Hello报文将被阻塞,接口上无法建立邻居关系。这样用户侧就无法窥探到网络中的OSPF报文。
 为什么需要M-LAG(为什么出现这门技术 why)
为什么需要M-LAG(为什么出现这门技术 why)