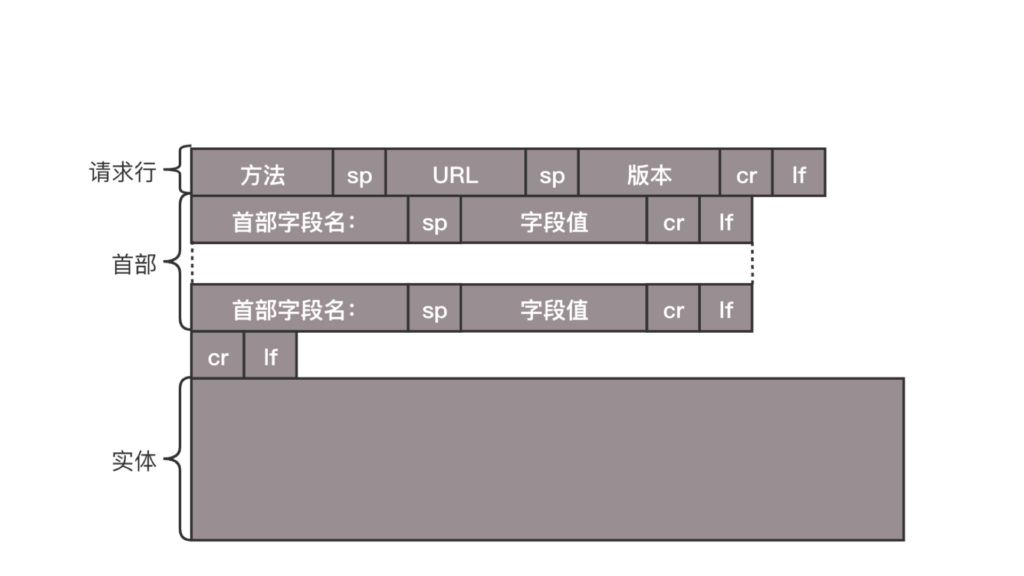
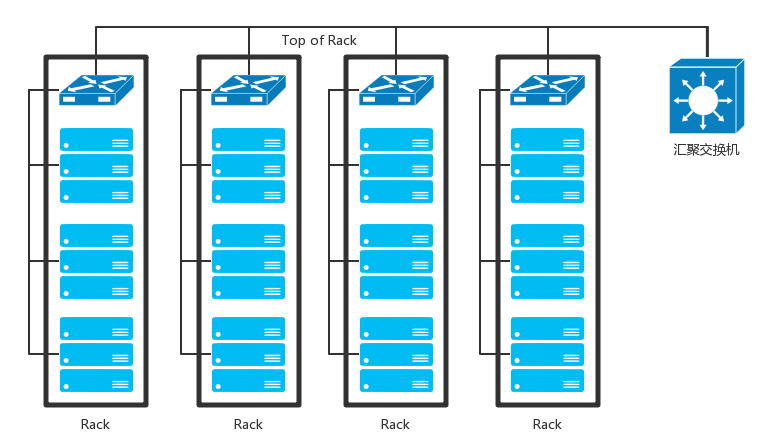
Rack 机架
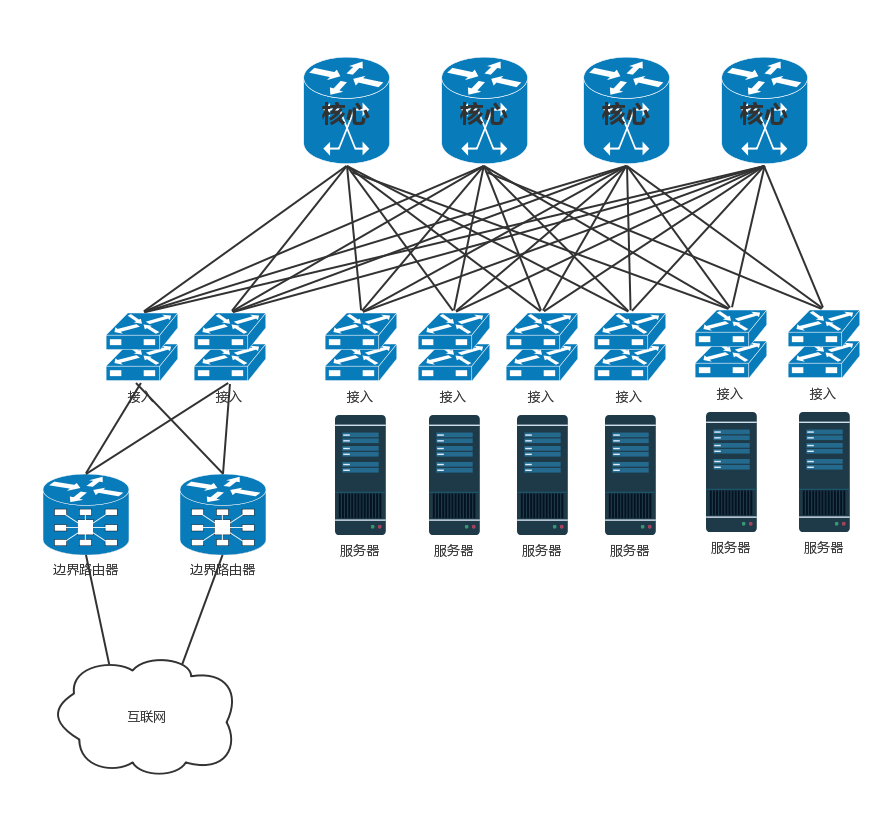
Border Router 边缘路由器:连接多个运营商
多线BGP 协议:既然是路由器,就需要跑路由协议,数据中心往往就是路由协议中的自治区域(AS)。数据中心里面的机器要想访问外面的网站,数据中心里面也是有对外提供服务的机器,都可以通过 BGP 协议,获取内外互通的路由信息。这就是我们常听到的多线 BGP 的概念。
TOR 交换机:这些交换机往往是放在机架顶端的,所以经常称为 TOR(Top Of Rack)交换机。这一层的交换机常常称为接入层(Access Layer)
Aggregation Switch 汇聚层交换机:当一个机架放不下的时候,就需要多个机架,还需要有交换机将多个机架连接在一起。这些交换机对性能的要求更高,带宽也更大。这些交换机称为汇聚层交换机(Aggregation Layer)。
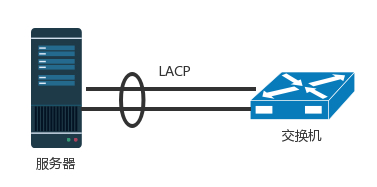
Bond 网卡绑定:如果网卡坏了,或者不小心网线掉了,机器就上不去了。所以,需要至少两个网卡、两个网线插到 TOR 交换机上,但是两个网卡要工作得像一张网卡一样,这就是常说的网卡绑定(bond)。
LACP(Link Aggregation Control Protocol):这就需要服务器和交换机都支持一种协议 LACP,它们互相通信,将多个网卡聚合称为一个网卡,多个网线聚合成一个网线,在网线之间可以进行负载均衡,也可以为了高可用作准备。
Stack 堆叠:将多个交换机形成一个逻辑的交换机,服务器通过多根线分配连到多个接入层交换机上,而接入层交换机多根线分别连接到多个交换机上,并且通过堆叠的私有协议,形成双活的连接方式。
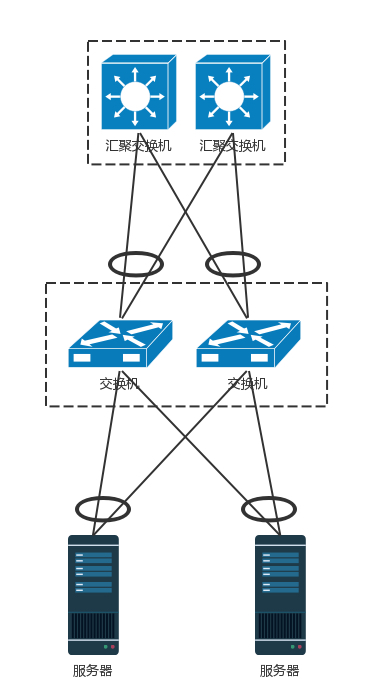
POD (交货点):汇聚层将大量的计算节点相互连接在一起,形成一个集群。在这个集群里面,服务器之间通过二层互通,这个区域常称为一个 POD(Point Of Delivery 交货点),有时候也称为一个可用区(Available Zone)。
Core Switch 核心交换机:当节点数目再多的时候,一个可用区放不下,需要将多个可用区连在一起,连接多个可用区的交换机称为核心交换机。核心交换机吞吐量更大,高可用要求更高,肯定需要堆叠,但是往往仅仅堆叠,不足以满足吞吐量,因而还是需要部署多组核心交换机。核心和汇聚交换机之间为了高可用,也是全互连模式的。
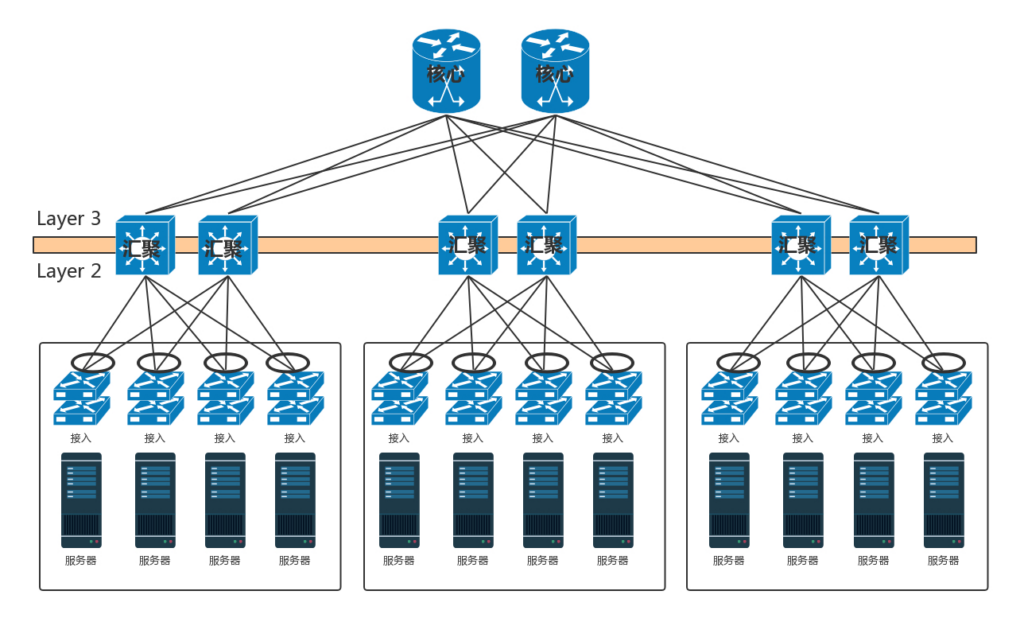
全互连模式下环路的问题:一种方式是,不同的可用区在不同的二层网络,需要分配不同的网段。汇聚和核心之间通过三层网络互通的,二层都不在一个广播域里面,不会存在二层环路的问题。三层有环是没有问题的,只要通过路由协议选择最佳的路径就可以了。
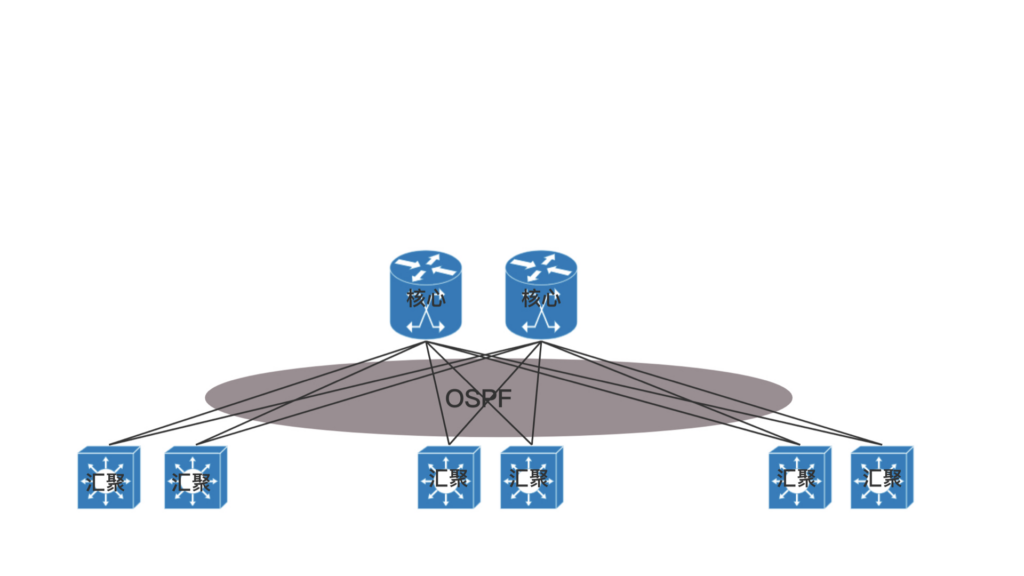
大二层:但是随着数据中心里面的机器越来越多,尤其是有了云计算、大数据,集群规模非常大,而且都要求在一个二层网络里面。这就需要二层互连从汇聚层上升为核心层,也即在核心以下,全部是二层互连,全部在一个广播域里面,这就是常说的大二层。
TRILL:如果大二层横向流量不大,核心交换机数目不多,可以做堆叠,但是如果横向流量很大,仅仅堆叠满足不了,就需要部署多组核心交换机,而且要和汇聚层进行全互连。由于堆叠只解决一个核心交换机组内的无环问题,而组之间全互连,还需要其他机制进行解决。于是大二层就引入了 TRILL(Transparent Interconnection of Lots of Link),即多链接透明互联协议。它的基本思想是,二层环有问题,三层环没有问题,那就把三层的路由能力模拟在二层实现。
RBridge:运行 TRILL 协议的交换机称为 RBridge,是具有路由转发特性的网桥设备,只不过这个路由是根据 MAC 地址来的,不是根据 IP 来的。
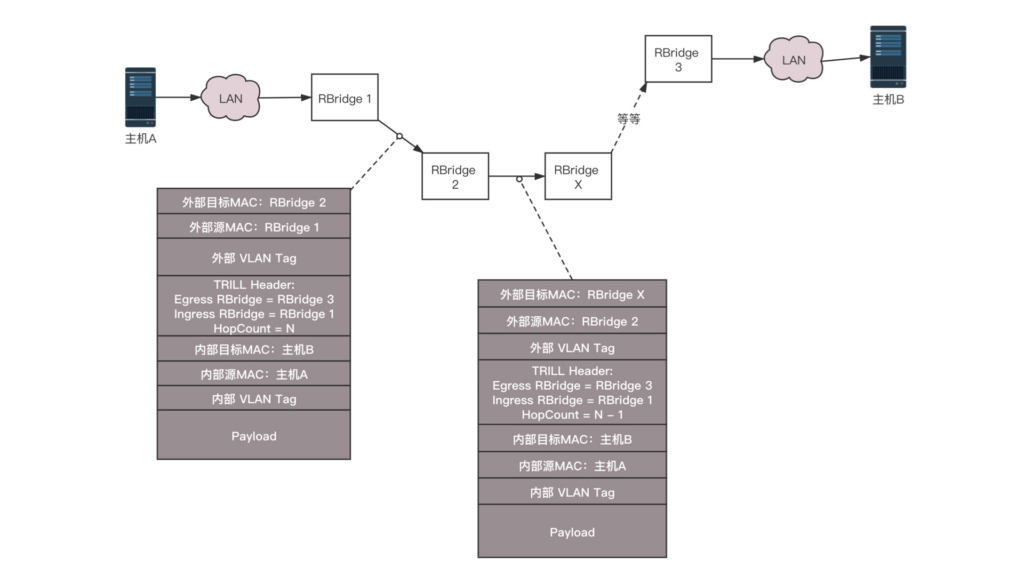
大二层的广播怎么分隔:对于大二层的广播包,也需要通过分发树的技术来实现。我们知道 STP 是将一个有环的图,通过去掉边形成一棵树,而分发树是一个有环的图形成多棵树,不同的树有不同的 VLAN,有的广播包从 VLAN A 广播,有的从 VLAN B 广播,实现负载均衡和高可用。
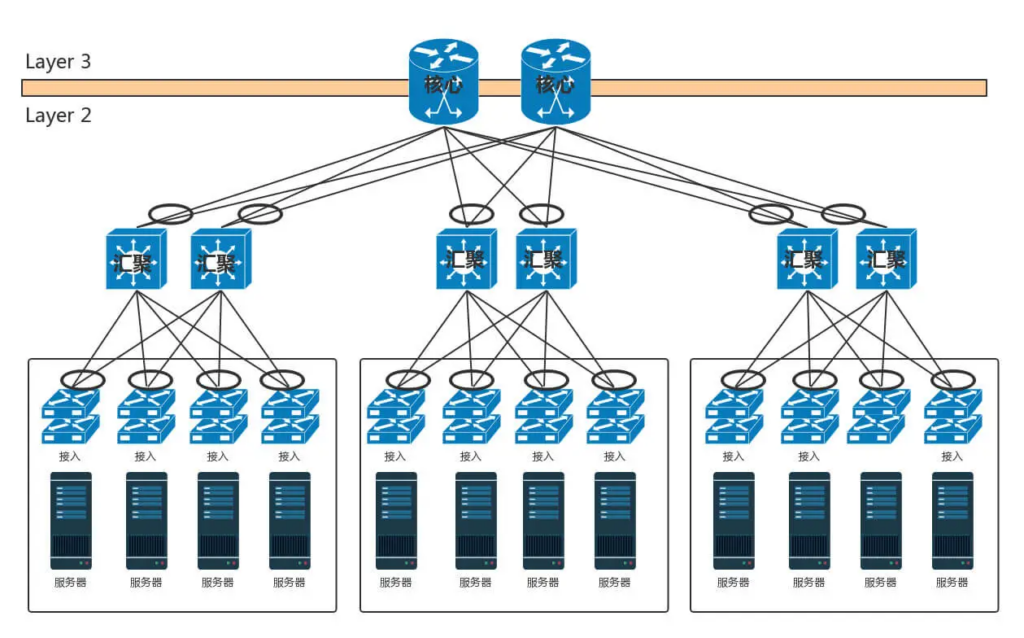
典型的数据中心网络架构:在核心交换上面,往往会挂一些安全设备,例如入侵检测、DDoS 防护等等。这是整个数据中心的屏障,防止来自外来的攻击。
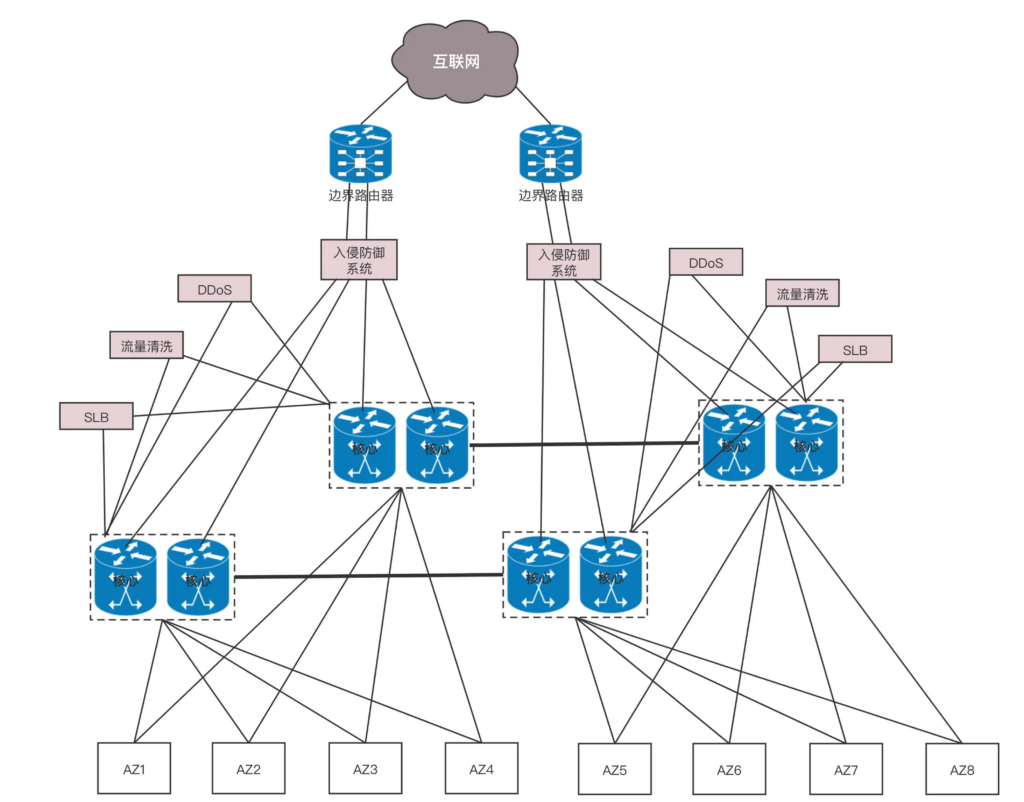
南北流量:这是一个典型的三层网络结构。这里的三层不是指 IP 层,而是指接入层、汇聚层、核心层三层。这种模式非常有利于外部流量请求到内部应用。这个类型的流量,是从外到内或者从内到外,对应到上面那张图里,就是从上到下,从下到上,上北下南,所以称为南北流量。
东西流量:但是随着云计算和大数据的发展,节点之间的交互越来越多,例如大数据计算经常要在不同的节点将数据拷贝来拷贝去,这样需要经过交换机,使得数据从左到右,从右到左,左西右东,所以称为东西流量。
(Spine/Leaf)叶脊网络:为了解决东西流量的问题,演进出了叶脊网络(Spine/Leaf)。
叶子交换机(leaf),直接连接物理服务器。L2/L3 网络的分界点在叶子交换机上,叶子交换机之上是三层网络。
脊交换机(spine switch),相当于核心交换机。叶脊之间通过 ECMP 动态选择多条路径。脊交换机现在只是为叶子交换机提供一个弹性的 L3 路由网络。南北流量可以不用直接从脊交换机发出,而是通过与 leaf 交换机并行的交换机,再接到边界路由器出去。