出口NAT 的问题:出口的时候,很多机房都会配置 NAT,也即网络地址转换,使得从这个网关出去的包,都换成新的 IP 地址,当然请求返回的时候,在这个网关,再将 IP 地址转换回去,所以对于访问来说是没有任何问题。但是一旦做了网络地址的转换,权威的 DNS 服务器,就没办法通过这个地址,来判断客户到底是来自哪个运营商,而且极有可能因为转换过后的地址,误判运营商,导致跨运营商的访问。
域名更新问题:例如双机房部署的时候,跨机房的负载均衡和容灾多使用 DNS 来做。当一个机房出问题之后,需要修改权威 DNS,将域名指向新的 IP 地址,但是如果更新太慢,那很多用户都会出现访问异常。
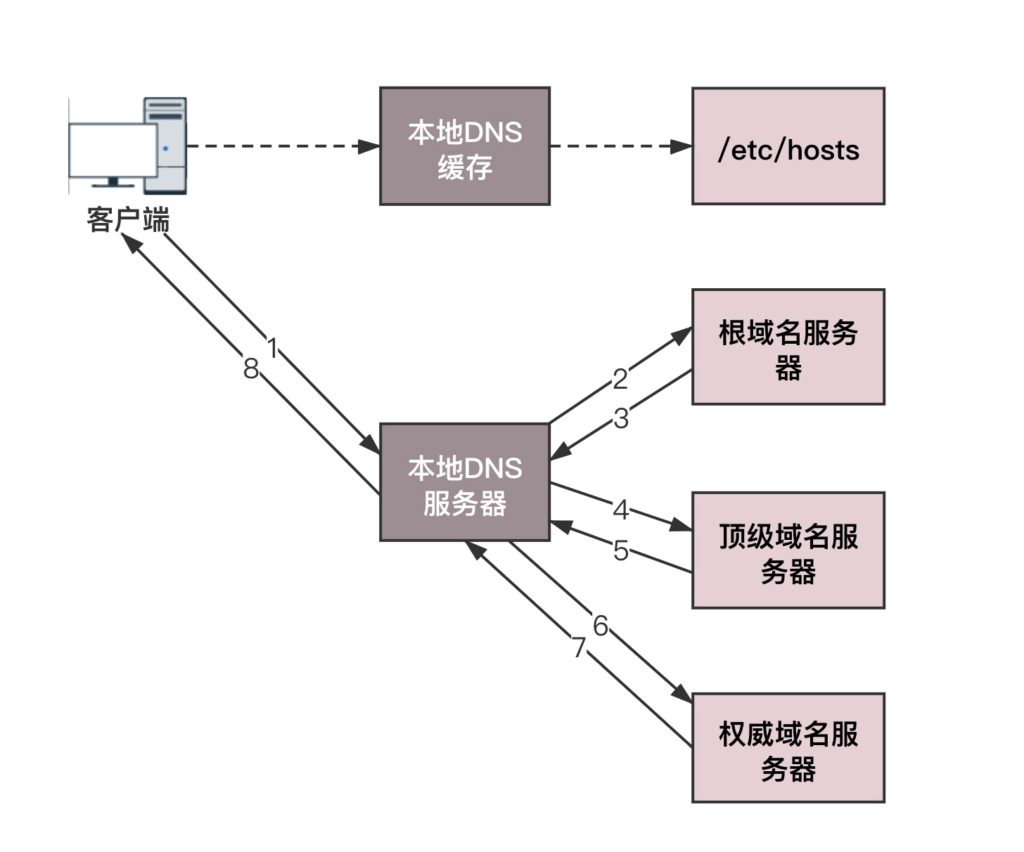
解析超时
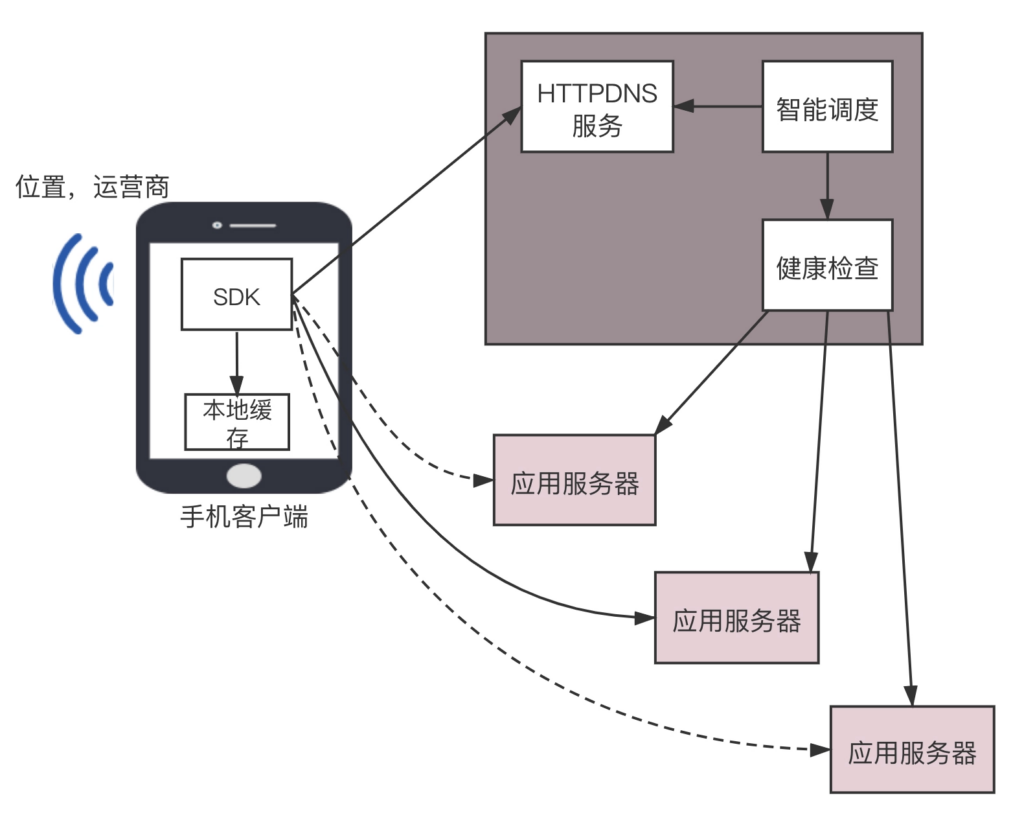
HttpDNS 的工作模式
HttpDNS 其实就是,不走传统的 DNS 解析,而是自己搭建基于 HTTP 协议的 DNS 服务器集群,分布在多个地点和多个运营商。
当客户端需要 DNS 解析的时候,直接通过 HTTP 协议进行请求这个服务器集群,得到就近的地址。这就相当于每家基于 HTTP 协议,自己实现自己的域名解析,自己做一个自己的地址簿,而不使用统一的地址簿。但是默认的域名解析都是走 DNS 的,因而使用 HttpDNS 需要绕过默认的 DNS 路径,就不能使用默认的客户端。使用 HttpDNS 的,往往是手机应用,需要在手机端嵌入支持 HttpDNS 的客户端 SDK。
例如,某个应用要访问另外一个应用,如果配置另外一个应用的 IP 地址,那么这个访问就是一对一的。但是当被访问的应用撑不住的时候,我们其实可以部署多个。但是,访问它的应用,如何在多个之间进行负载均衡?只要配置成为域名就可以了。在域名解析的时候,我们只要配置策略,这次返回第一个 IP,下次返回第二个 IP,就可以实现负载均衡了。
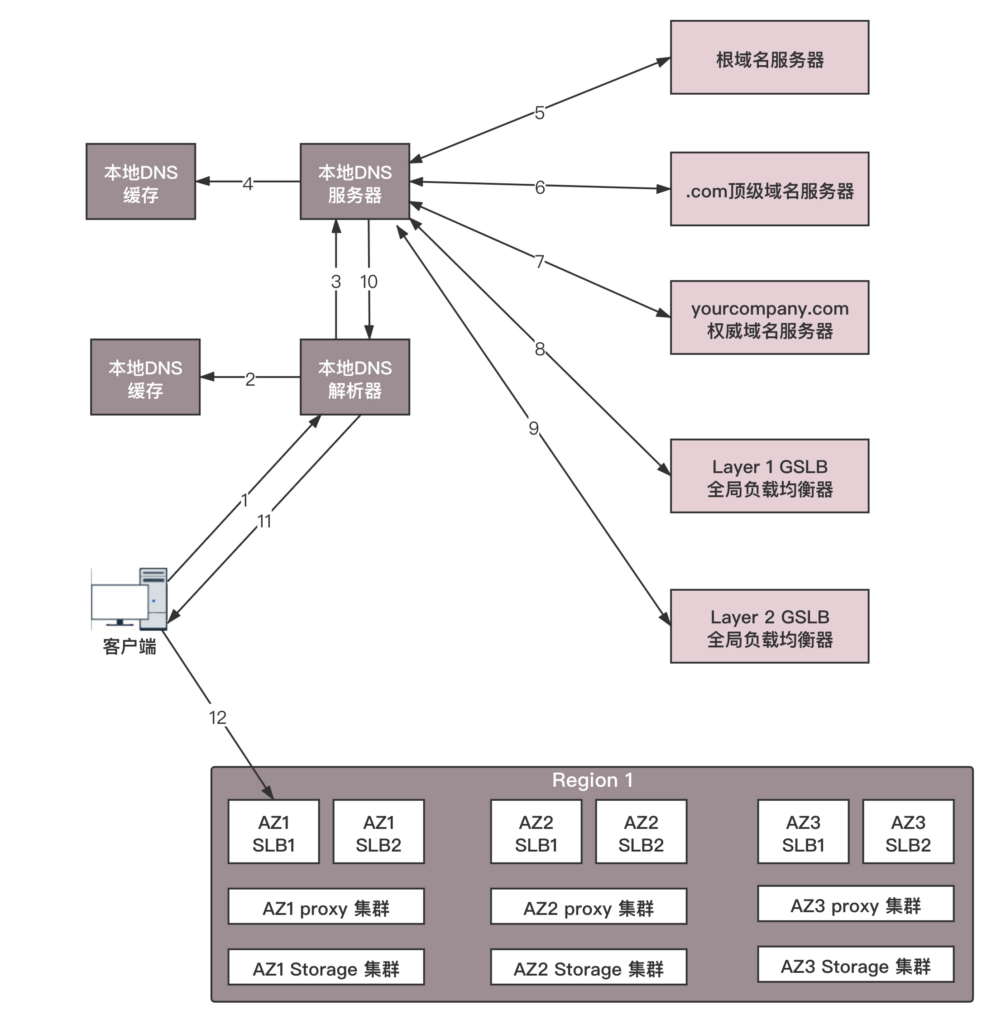
全局负载均衡
为了保证我们的应用高可用,往往会部署在多个机房,每个地方都会有自己的 IP 地址。当用户访问某个域名的时候,这个 IP 地址可以轮询访问多个数据中心。如果一个数据中心因为某种原因挂了,只要在 DNS 服务器里面,将这个数据中心对应的 IP 地址删除,就可以实现一定的高可用。