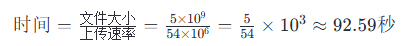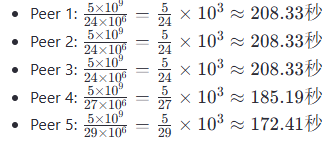1、IANA在可聚合全球单播地址范围内指定了一 个格式前缀来表示IPv6的6to4地址,该前缀为()
IANA(Internet Assigned Numbers Authority,互联网号码分配局)为6to4这种IPv6过渡技术指定了一个特殊的地址前缀。6to4是一种用于帮助网络从IPv4平滑过渡到IPv6的技术,它允许IPv6数据包封装在IPv4数据包中进行传输。
对于6to4地址,IANA指定的格式前缀为2002::/16。这意味着所有合法的6to4 IPv6地址都将以2002这四个字符开始。之后的部分通常包含了IPv4地址,用来标识支持6to4的路由器。
2、在IPv6 地址无状态自动配置过程中,主机首先必须自动形成一个唯一的(接口ID),然后向路由器发送请求报文,以便获得由路由器提供的地址配置信息。
先形成一个链路本地单播地址
4、PPTP 协议必须基于什么协议
PPTP(Point-to-Point Tunneling Protocol,点对点隧道协议)是一种用于实现虚拟专用网络(Virtual Private Network, VPN)的技术。PPTP允许远程用户通过公共网络(如互联网)建立安全的连接到企业内部网络。它是最早的广泛使用的VPN技术之一,尤其受到Windows操作系统用户的欢迎,因为Windows系统内置了对该协议的支持。
以下是PPTP的一些关键特性:
- 安全性:PPTP使用了微软开发的MS-CHAP v2(Microsoft Challenge Handshake Authentication Protocol version 2)作为默认的身份验证方式。虽然这提供了基本的安全保障,但是PPTP的安全性相比其他现代协议(如OpenVPN或L2TP/IPsec)来说较弱。
- 兼容性:由于PPTP得到了广泛的支持,尤其是在早期的Windows版本中,所以它可以在许多不同的操作系统和设备上使用。
- 速度:PPTP通常比其他协议更快,因为它使用较少的加密和认证步骤。不过,这也意味着它的安全性较低。
- 设置简便:PPTP易于设置和配置,特别是在Windows操作系统中。
- 隧道协议:PPTP基于PPP(Point-to-Point Protocol),并通过TCP(Transmission Control Protocol)端口1723来建立连接,同时使用通用路由封装(Generic Routing Encapsulation, GRE)来传输数据。
5、原站收到“在数据包组装期间生存时间为0”的ICMP报文,出现的原因是( )。
在IP报文传输过程中出现错误或对方主机进行探测时发送ICMP报文。ICMP报文报告的差错有很多种,其中源站收到“在数据包组装期间生存时间为0”的ICMP报文时,说明IP数据报分片丢失。IP报文在经历MTU较小的网络时,会进行分片和重装,在重组路由器上对同一分组的所有分片报文维持一个计时器,当计时器超时还有分片没到,重组路由器会丢弃已到的该分组的所有分片,并向源站发送“在数据包组装期间生存时间为0”的ICMP报文。
6、IPV4 IHL 字段的含义
在IPv4报文中,IHL(Internet Header Length)字段表示IPv4头部的长度,单位为4字节。这个字段告诉接收方IPv4头部有多少个32位字长,即头部总共有多少个4字节。例如,如果IHL值为5,则IPv4头部的长度就是5×4=20字节;如果IHL值为6,则头部长度为6×4=24字节。这是因为IPv4头部可能包含可选部分,而这些可选部分的长度不是固定的,所以需要用IHL来指示头部的实际大小。
IP数据报头长度(Internet Header Length,IHL)对应的4bit,可取的最大值是15,但是单位时4字节,因此最大数值是60字节。
IHL字段位于IPv4头部的第二个字节,高四位表示IHL,低四位表示服务类型TOS(Type of Service)的保留位,通常置为0。在解析IPv4报文时,IHL是非常重要的,因为它决定了如何正确地解析和处理IPv4头部的各个字段。如果IHL值太小,可能会导致忽略掉一些必要的头部字段,从而影响后续的数据包处理。同样,如果IHL值太大,那么就可能存在无效的数据,这可能是由于错误的配置或者恶意攻击造成的。因此,正确的IHL值对于保证IPv4报文的正常传输至关重要。
7、DHCP 自动分配与动态分配的区别
DHCP 自动分配是客户端使用的是固定的地址,动态分配是客户端使用动态的地址。
8、IP数据报分片
假设一个IP数据报总长度为4000B,要经过一段MTU为1500B的链路,该IP数据报必须经过分片才能通过该链路。
IP报文的标记字段(Flag)长度为3位,第1位不使用;第2位是不分段(DF)位,值为1表示不能分片,为0表示允许分片;第3位是更多分片(MF)位,值为1表示之后还有分片,为0表示是最后一个分片。
IP报文的分片偏移字段(Fragment Offset)是标识所片的分组分片之后在原始数据中的相对位置,表示数的单位是8字节,即每个分片长度是8字节的整数倍。所以,第三片(最后一片)的偏移字段值=(MTU-IP头部长度)×(分片数-1)÷8=(1500-20)×2÷8=370。
9、IPV4组播 MAC地址
组播IP地址230.20.88.76对应的组播MAC地址是 01-00-5E-14-58-4c
组播IPv4地址对应的组播MAC地址的高25bit是固定的(其中高24bit是0x01005e,第25个比特位为0),而剩余的23bit则从其对应的组播IPv4地址的低23bit拷贝而来。注意:IP地址是十进制,MAC地址是十六进制,因此后23位映射时需要转成16进制,可以先把十进制转成二进制再转成十六进制。
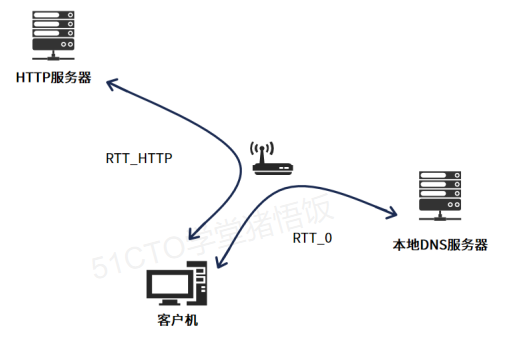
10、计算HTTP 时间
如下图所示,假设客户机通过浏览器访问HTTP服务器试图获得一个Web网站,关联于URL的IP地址在其本地没有缓存,假设客户机与本地DNS服务器之间的延迟为RTT_0=1ms,客户机与HTTP服务器之间的往返延迟为RTT_HTTP=32ms,不考虑页面的传输延迟。若该Web页面只包含文字,则从用户点击URL到浏览器完整页面所需要的总时间为(54);若客户机接着访问该服务器上另一个包含10个图片的Web页面,采用HTTP/1.1流水线访问方式,客户机发送请求的速度为1ms,则上述时间为(55)。
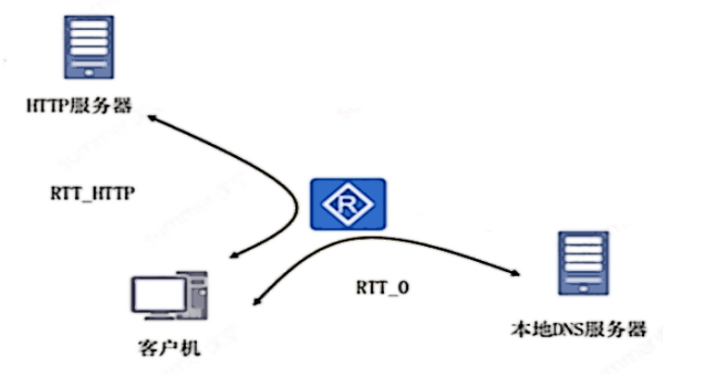
本题是一个综合应用题,在web浏览器点击网址时,通常先去DNS服务器解析出网址中服务器的IP地址,再使用HTTP协议去访问web服务器,但是进行HTTP访问时,需要先建立TCP连接。另外要注意的一点是,HTTP 1.1 支持持续连接,也就是客户端和服务器端在第一次通讯时需要建立TCP连接,接下来如果客户端访问的是同一个服务器上的其他web页面,可以不再建立TCP连接,而使用原来已经创建的TCP连接,因此可以节省建立TCP连接所消耗的时间。在第一次访问时,由于没有DNS缓存信息,所以其访问时间由以下三部分组成:
1. dns解析时间1ms;
2. 建立TCP连接的时间RTT;
3、请求并传输页面时间RTT;
所以第一次访问的总时间是1+32+32=65ms
接着继续访问时,由于使用的HTTP 1.1 ,因此使用的是持续连接,在访问web页面有多个图片时,HTTP 1.1基于流水线的方式,所以在上一个TCP连接的基础上,所以省去了第一次访问的1和2这两部分的时间,只有请求页面和响应的往返时间,根据选项,采用了HTTP1.1的持续连接的流水线方式,一个基础界面+10个图片,由于客户就发送请求的速度时1个/ms,采用流水线方式,传输11个请求的时间=32+10*1个/ms=42ms。
11、ARP 广播次数
如下图所示,PC1和PC2通过路由器R进行通信,假设图中各设备的ARP表初始均为空,PC1通过ping命令对PC2进行网络连通性测试,顺利收到PC2的回信息,至少经过(2)次ARP广播。
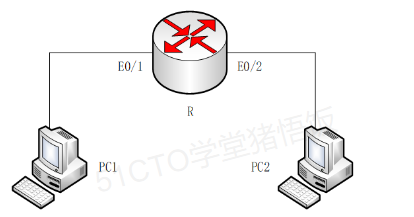
PC1发送数据给PC2,首先需要通过ARP获得R的E0/1接口的MAC地址,R转发数据给PC2需要通过ARP获得PC2的MAC地址。PC2返回数据到PC1亦然。所以共4次。
假设一个IP数据报总长度为4000B,要经过一段MTU为1500B的链路,该IP数据报必须经过分片才能通过该链路。
4000/(1500-20)=